Microsoft Failover Clustering 2-ci hissə
Hərkəsə salamlar, Microsoft Failover Clustering məqaləmin birinci hissəsində cluster haqqında məlumat verib 2 node-lu Hyper-V cluster qurmuşduq. Bu məqaləmdə mövcud Hyper-V cluster-im üzərində cluster xidməti haqqında danışmağa davam edəcəyəm.
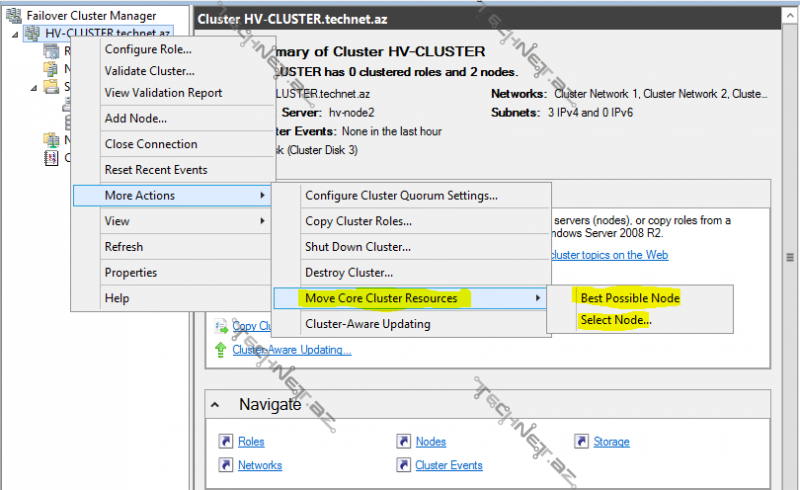
Failover Cluster Manager konsolu köməyilə mövcud cluster-imizin üzərində sağ düymə ilə açılan menyuya nəzər salaq:
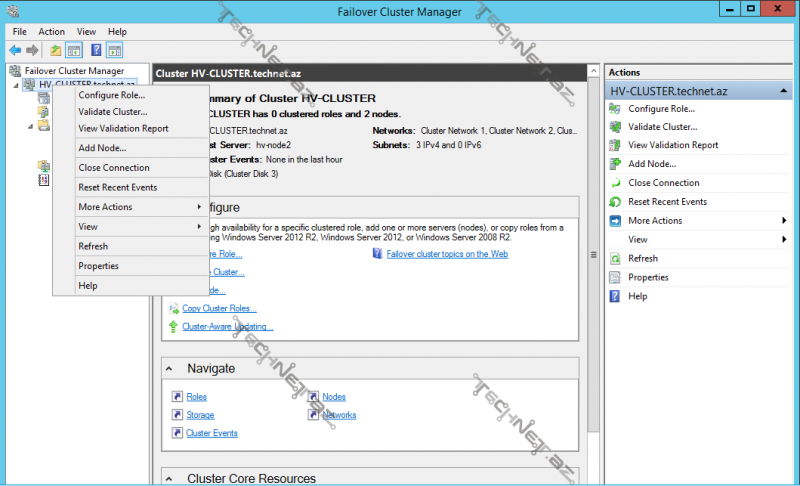
Configure role– cluster üzərindəki hansı role-un yüksək əlçatanlıqla çalışacağını müəyyən edirik həmin role- clustered role adlanır:
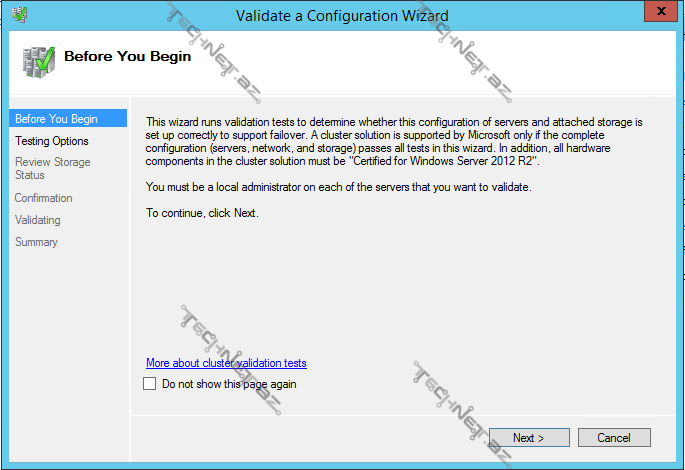
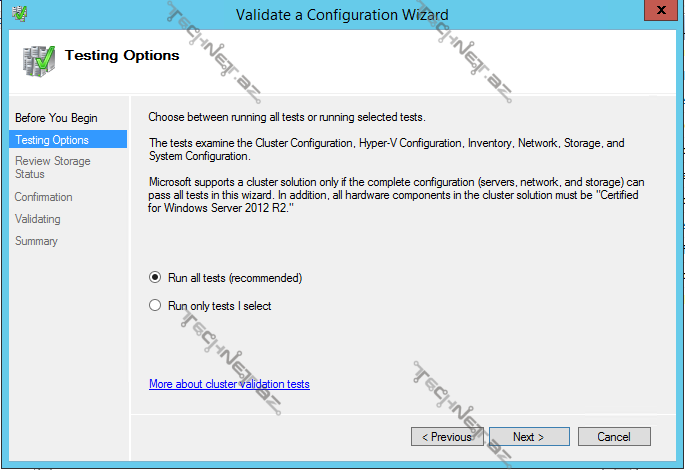
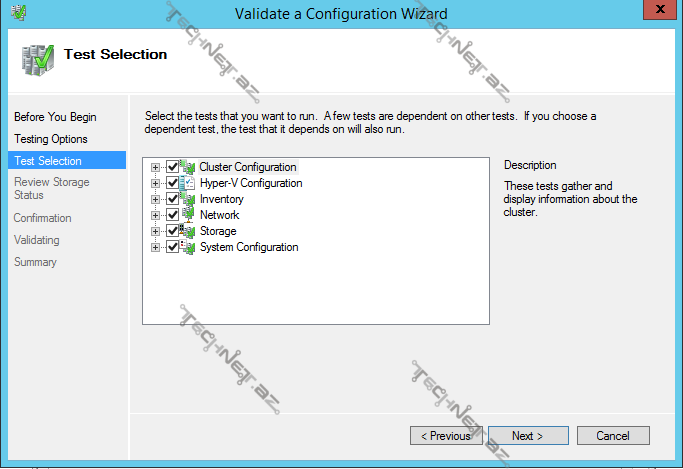
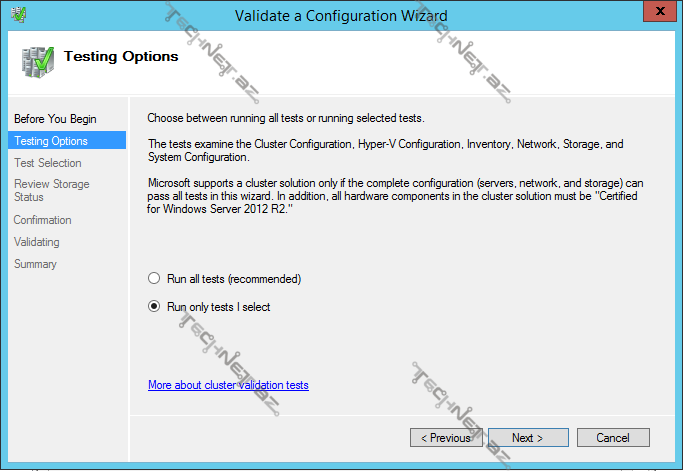
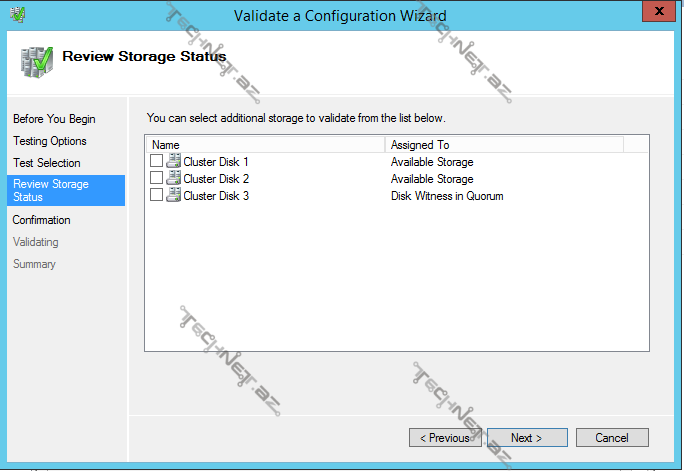
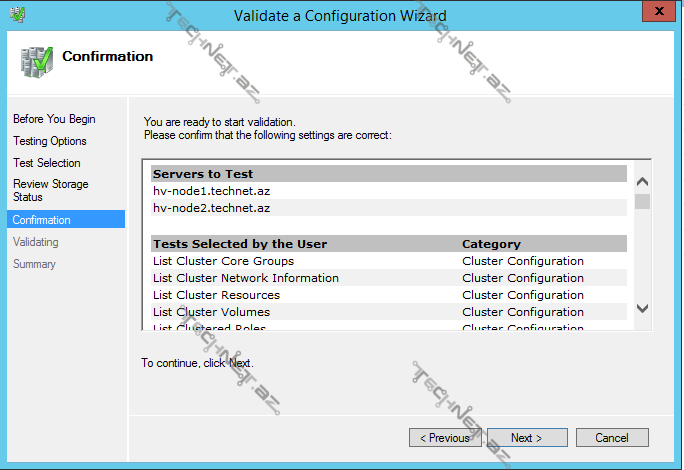
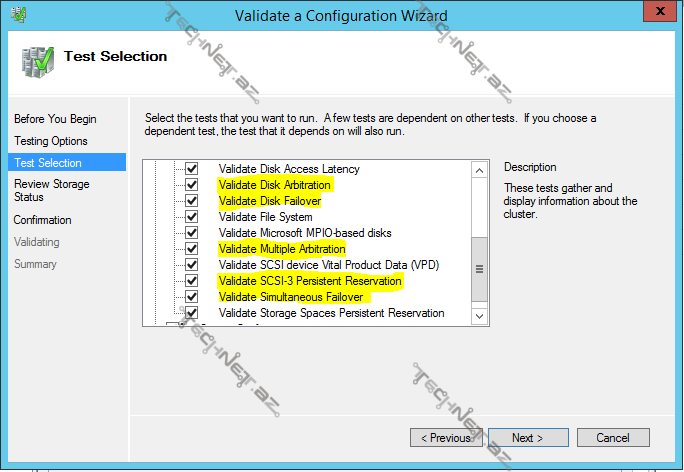
Validate Cluster– cluster üzərində hər hansı bir əməliyyat (məs. yeni bir node və ya disk əlavə etdikdə) apardıqdan sora cluster-in sabit çalışıb çalışmayacağını müəyyən etmək üçün cluster konfiqurasiyasını doğrulamağımız gərəkdir. Storage testləri daxilindəki aşağıdakı testlər downtime-a səbəb olur ona görə də storage-ə yeni bir disk əlavə etmək istisna olmaqla həmin testləri etməyə də bilərsiniz:
-Validating Disk Arbitration
-Disk Failover
-Multiple Arbitration
-SCSI-3 Persistent Reservation
-Simultaneous Failover
Gördüyümüz kimi eyni zamanda bütün testləri və ya seçilmiş testləri həyata keçirə bilərik.
Add node– cluster-a yeni bir node əlavə edə bilərik;
More Actions bölməsində
Confiqure Cluster Quorum Settings – cluster qurularlən quorum tənzimləmələri avtomatik olunur, istəsək bu seçimlə biz sonradan da edə bilərik,
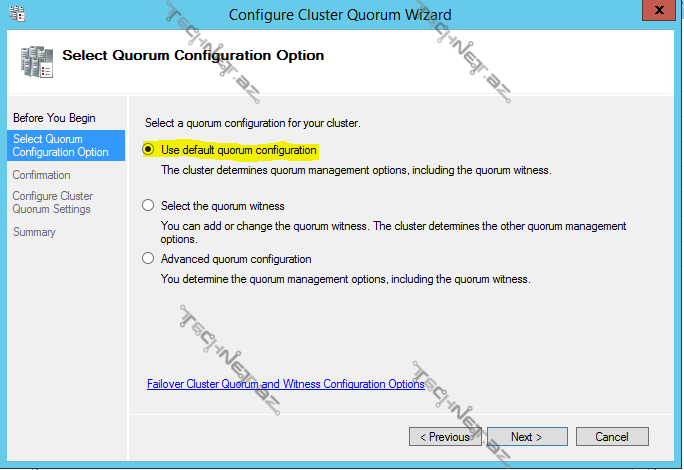
birinci seçimdə cluster özü quorum konfiqurasiyasını tənzimləyir, ikinci seçimdə biz əlavə olaraq səs hüququna malik witness əlavə edə və ya dəyişdirə bilərik, next ilə davam edək:
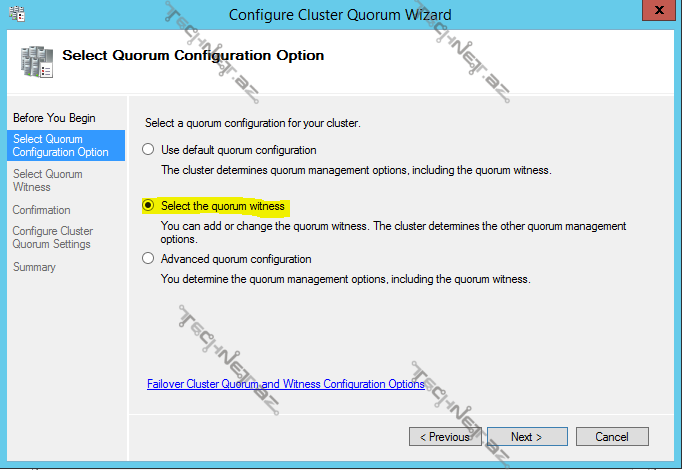
gördüyümüz kimi winess kimi disk, file share müəyyən edə bilərik ya da ümumiyyətlə müəyyən etməyə də bilərik:
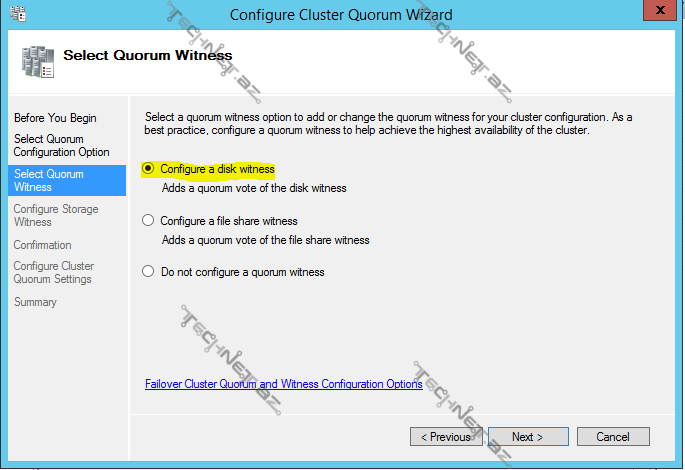
disk witness seçdiyimiz zaman movcud disklərdən birini seçərək davam edə bilərik: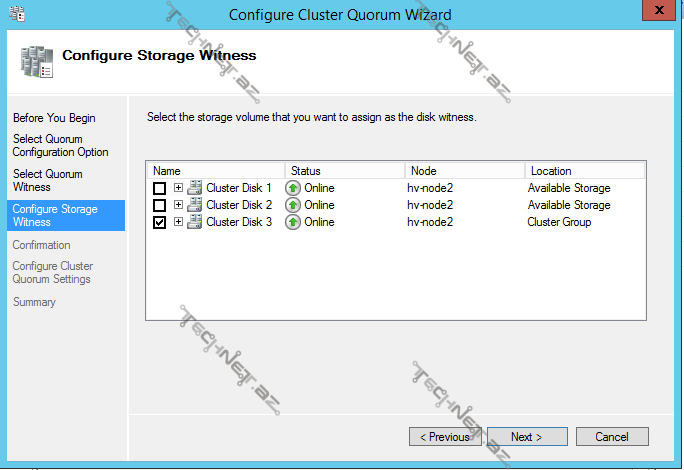
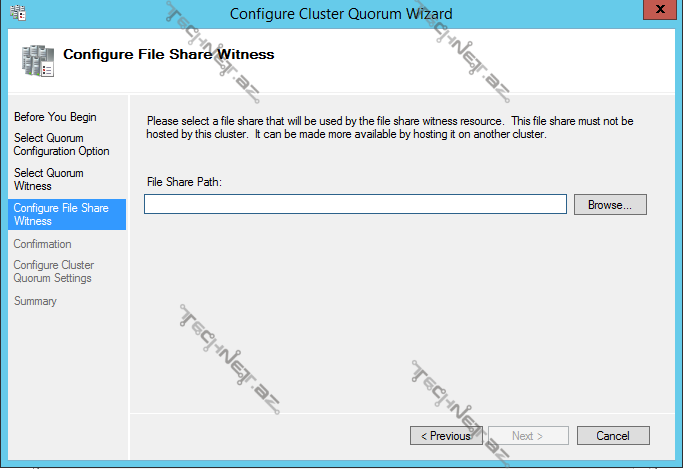
file share witness dediyimiz zaman isə mövcud paylaşmış bir file share seçərək davam edə bilərik:
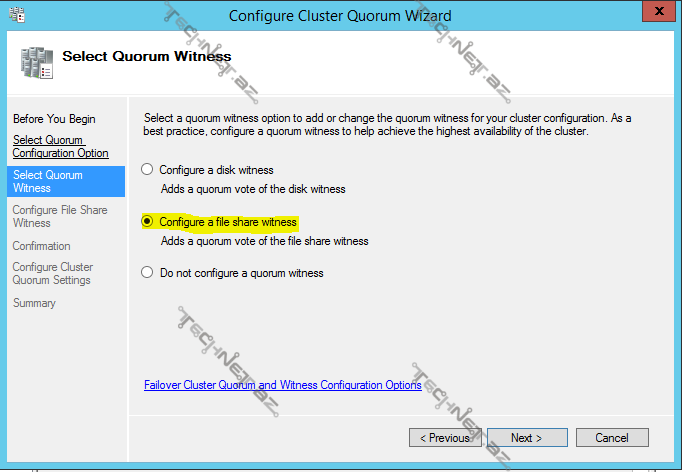
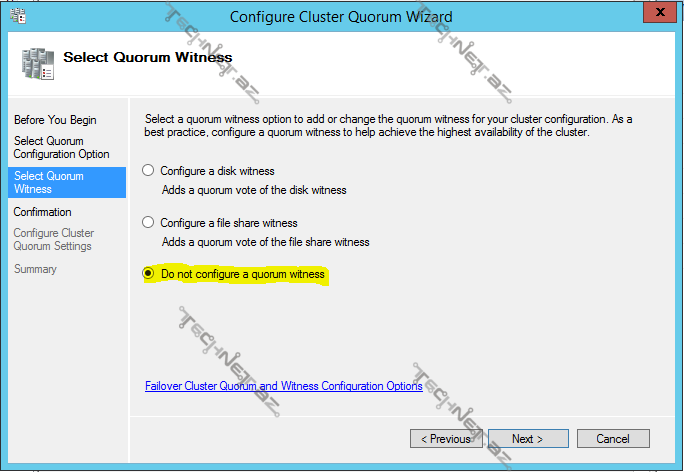
do not configure a quorum witness – bu bölmədə isə mövcud node-larımızdan səs hüququnu ala və ya verə və həm də sadəcə witness-in bu hüquqa malik olmasını məyyən edə bilərik. Witness-i itirdiyimiz zaman cluster-i da itirmiş olarıq:
Eyni zamanda more actions– bölməsindən istifadə edərək cluster-i stop və məhv edə bilərik:
Cluster Aware Updating – bu özəllik ilə birlikdə növbəli bir şəkildə cluster-a daxil olan node-larımızı update edə bilərik. İlk öncə node-lardan biri maintenance mode-a keçir- node-un cluster manager konsolu üzərinəki statusu paused şəklində görünür, update-lər yüklənib, node restart edib yenidən cluster üzərində online olduqdan sonra digər node-da eyni proses başlıyır və beləcə cluster-a daxil olan bütün nodelar üzərində təkrarlanır. Cluster Aware Updating bölməsinə daxil olduğumuz zaman aşağıdakı pəncərə ilə qarşılaşırıq:
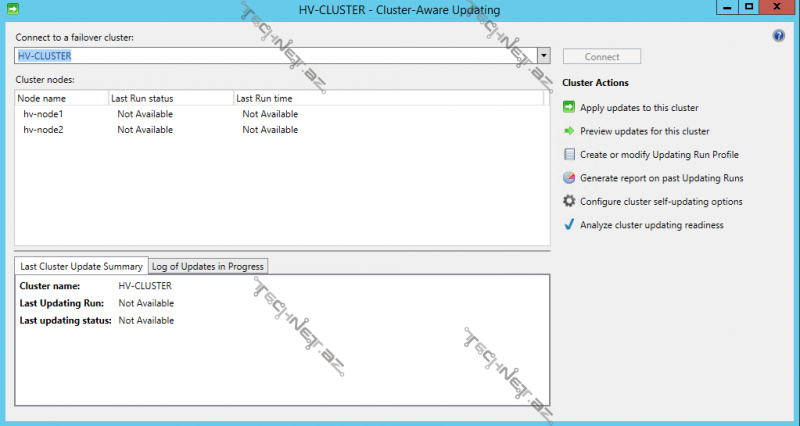
Preview updates to this cluster deyərək cluster-ə daxil olan node-lar üzərinə yüklənəcək update-lərin siyahısını yaradaq, bunun üçün generate update preview list deyirik:
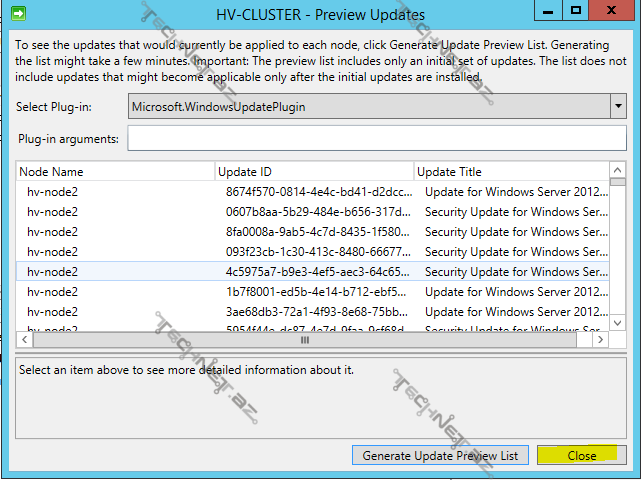
indi isə Apply updates to this cluster deyərək davam edək:
bu zaman aşağıdakı pəncərə ilə rastlaşacağıq, next ilə davam edirik:
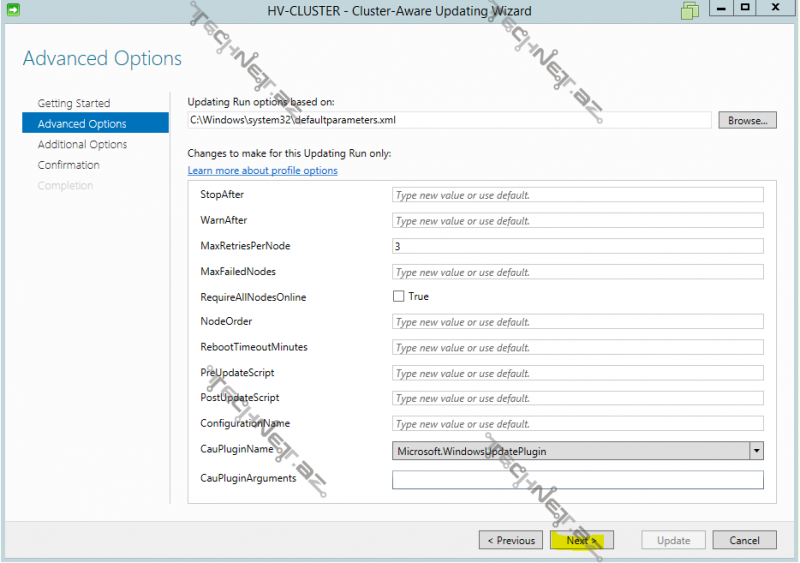
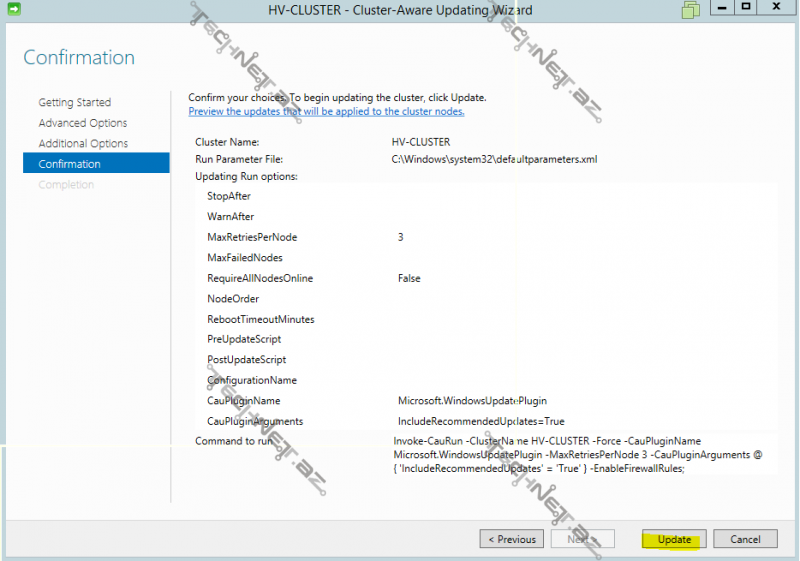
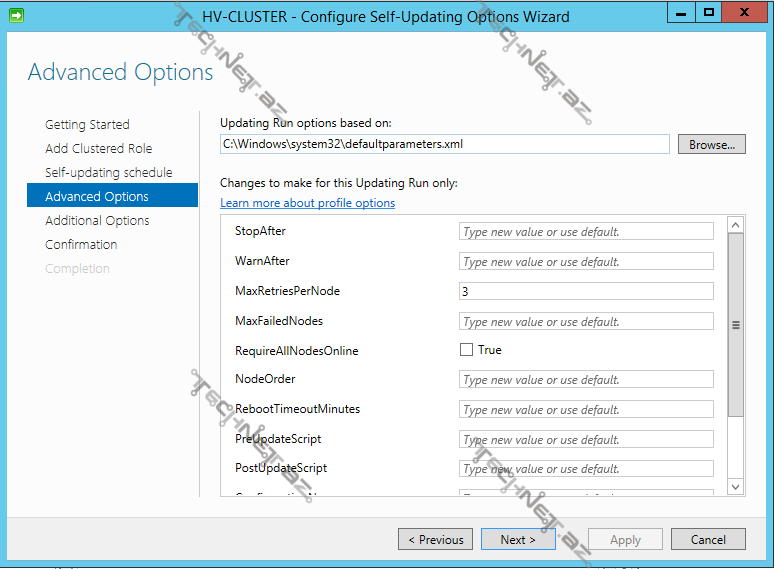
burda Cluster Aware Updating-lə bağlı bir sıra parametrləri müəyyən edə bilərik:
StopAfter – bu müddət sonunda update prosesi ləğv olunur
WarnAfter– update prosesinin xəbərdarlıq müddəti
MaxRetriesPerNode– hər node üçün update-in yenidən yüklənmənin yoxlanması sayı
MaxFailedNodes– update prosesinin uğursuz ola biləcəyi node sayı
RequireAllNodesOnline– bütün node-ların online olması
NodeOrder– update prosesinin baş verəcəyi node sıralaması
RebootTimeoutMinutes-restart sonrası online olması üçün lazım olan vaxt
PreUpdateScript– update öncəsi işə salınacaq powershell scripti
PostUpdateScript-update sonrası işə salınacaq powershell scripti
ConfigurationName– powershell konfiqurasiya adı
CauPluginName– Cluster Aware Updating (CAU) tənzimləmələrinin saxlandığı plugin
CauPluginArguments– CAU plugin-inin parametrləri
next deyərək davam edirik:
sonda update deyərək prosesi başladırıq:
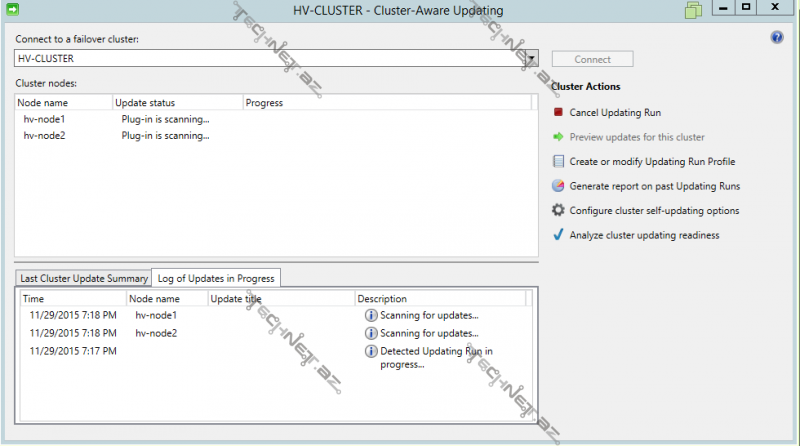
gördüyümüz kimi update-lər hər node üçün internetdən yüklənməyə başlandı:
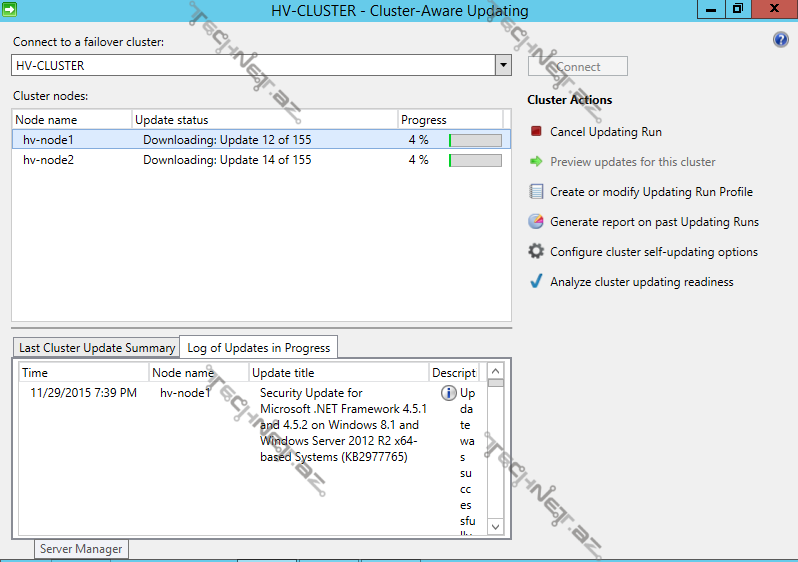
gördüyümüz kimi artıq 2-ci node üzərində update-lərin qurulum prosesi başlandı:

node-artıq maintenance mode-dadır və statusu- paused:

2-ci node update-lərin qurulumu bitdikdən sora restart edib yenidən online olduqdan sonra eyni proses 1-ci node-da başlayır:
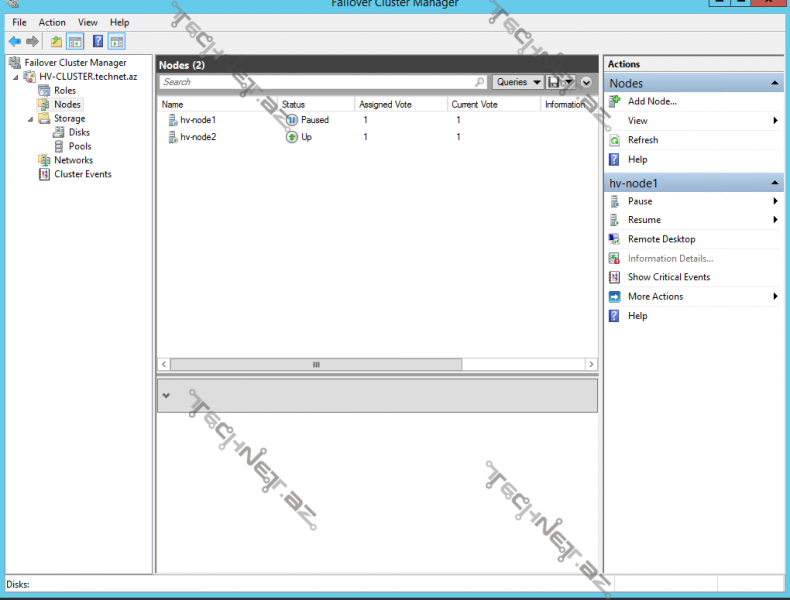
Nəticədə node-larımızın statusu isə aşağıdakı kimi görünməlidir:

Configure cluster self-updating options – bu seçimlə müəyyən tənzimləmələr edərək bu prosesi avtomatlaşdıra bilərik:

next ilə davam edirik:
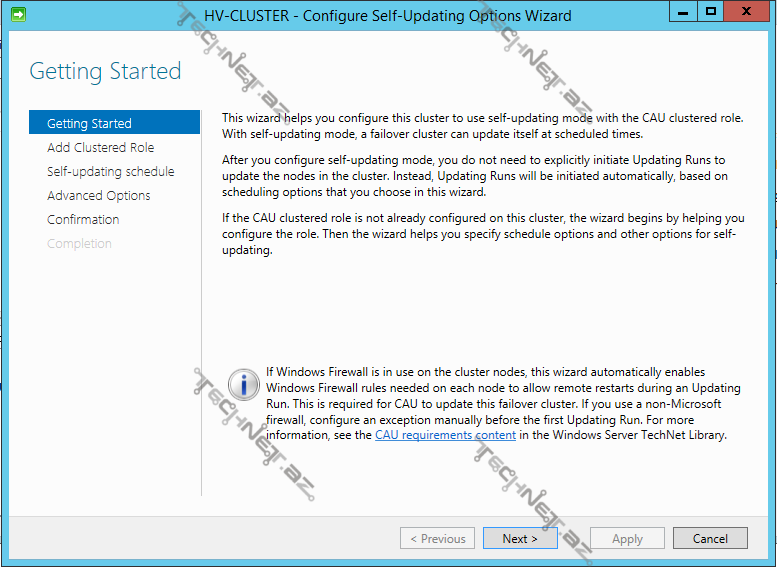
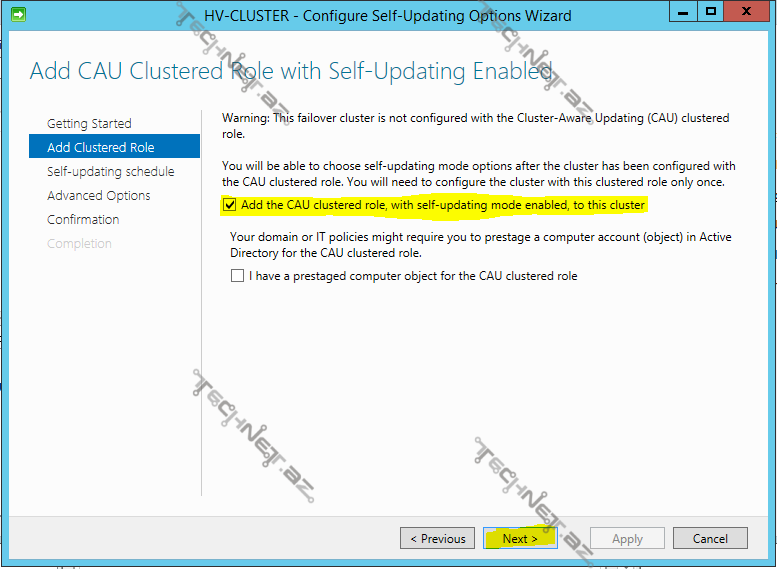
Self-updating əvvəldə danışdığımız clustered role-lar kimi fəaliyət göstərir ona görə də ilk olaraq bizim həmin role-u əlavə eləməyimiz bildirilir, hər yeni clustered role üçün active directory üzərində yeni bir obyekt yaradılır, əgər daha əvvəldən clustered role üçün computer obyektimiz varsa ikinci seçimi seçirik, lakin biz bunu ilk dəfə etdiyimiz üçün sadəcə ilk seçimi seçib davam edirik:
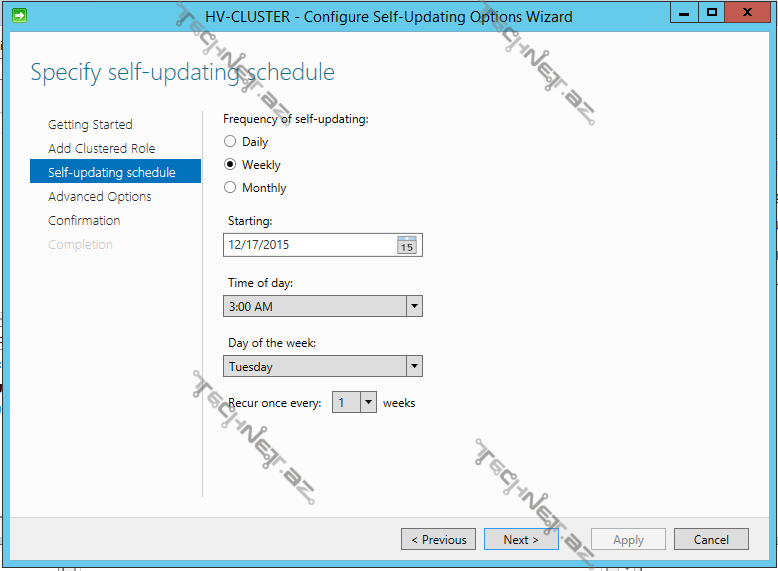
daha sonra self-updating üçün cədvəl müəyyən edə bilərik :
daha əvvəl bu barədə danışdığımız üçün davam edirik:
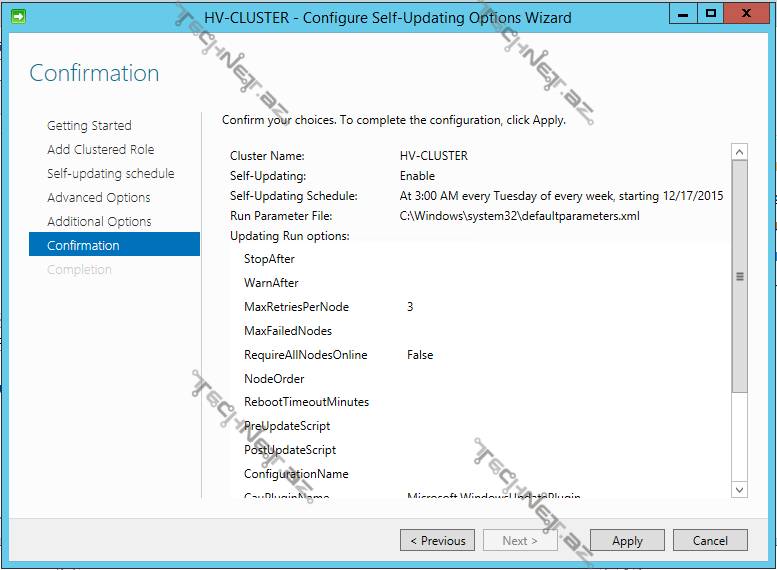
apply deyərək tənzimləməni sonlandırırıq:
Hər hansı bir node-u maintenance mode-a almaq üçün pause seçimimizdə Drain Roles -deyərək role-ları üzərindən buraxa bilərik ( bu zaman role-lar digər node-un üzərinə keçir) ya da Do Not Drain Roles deyərək buraxmaya da bilərik;
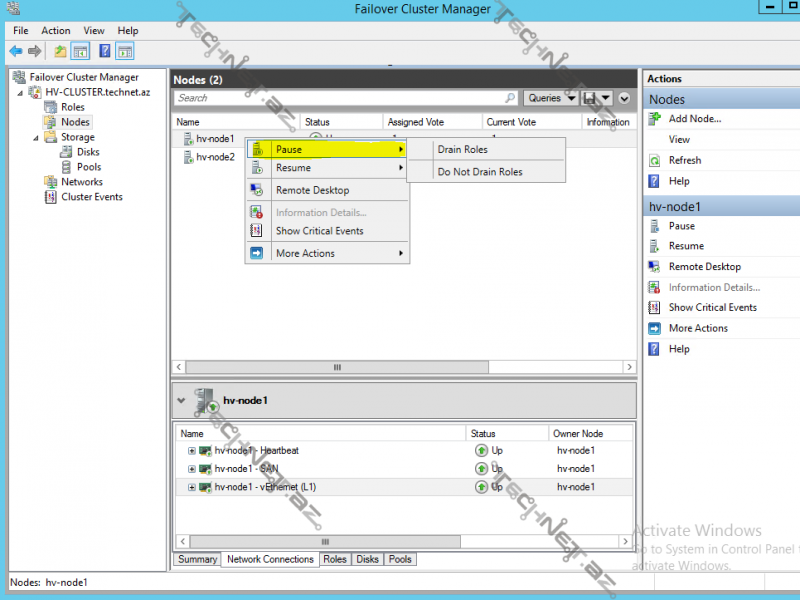
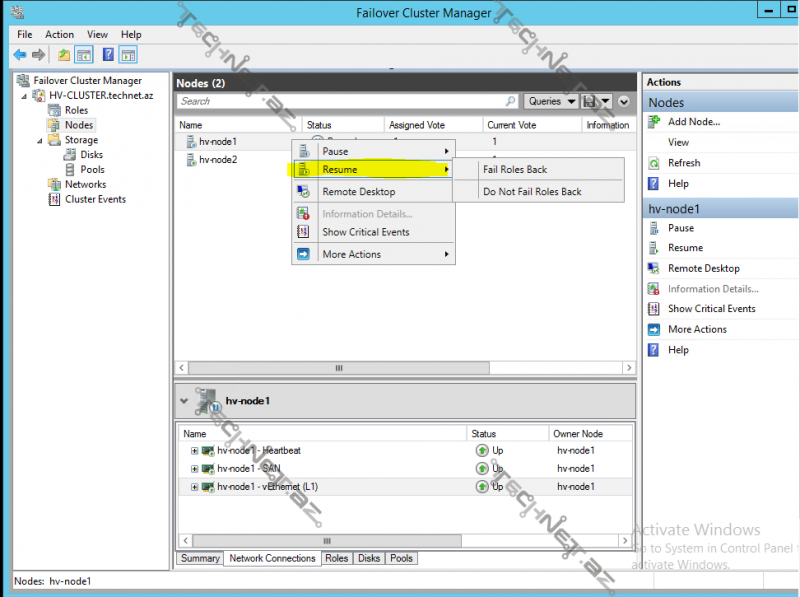
node-u yenidən online vəziyyətinə qaytarmaq üçün Resume dediyimizdə ya yenidən role-ları öz üzərinə al- Fail Roles Back, ya da yox alma –Do Not Fail Roles Back seçimlərimiz mövcud:
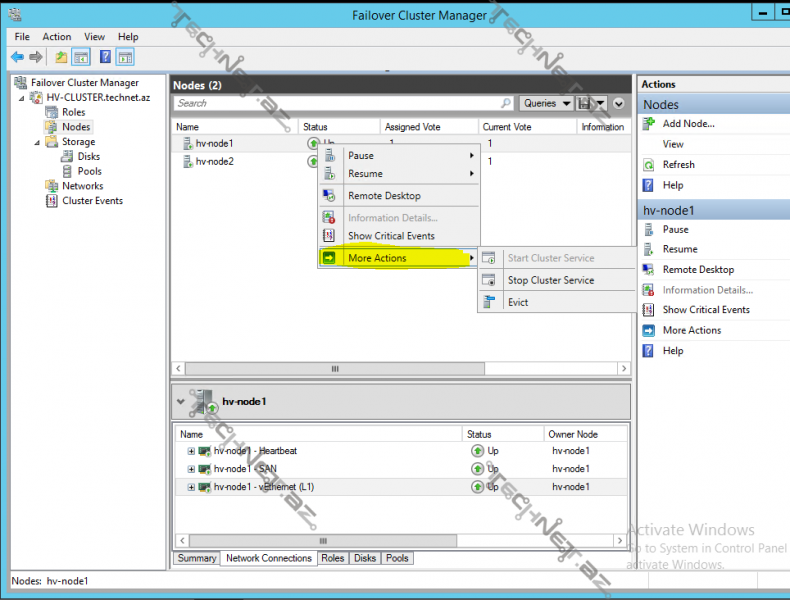
aşağıdakı seçimlərlə isə cluster servisini dayandıra və node-u cluster-dan xaric edə bilərik:
Məqalənin 2-ci hissəsini burada bitirirəm, 3-cü hissədə görüşənədək, yararlı olması diləyilə…



Şərhlər ( 1 )
Ətraflı məlumat üçün çox sağ olun. Uğurlar 🙂