T-SQL sorğularının optimallaşdırılması. 1-ci hissə
Salam Dostlar!
Əvvəlki dərslərimizdə qeyd etdik ki, T-SQL standart SQL əsasında qurulub və o da öz növbəsində (relational) münasibətli modelinə əsaslanır. Lakin çox vaxt SQL, o cümlədən T-SQL, bu nəzəriyyədən kənara çıxır. Buna baxmayaraq kodun maksimal olaraq münasibətli (relational) modelinə uyğun yazılması üçün T-SQL daxilində kifayət qədər imkanlar vardır. Keçən dərslərimizdə qeyd etdik ki, verilənlər bazasında cədvəllər münasibətli çoxluqlar şəklində təşkil olunub. Çoxluq isə bütöv bir halda istifadə olunur. Buna görə də T-SQL kodunu yazarkən, əgər mümkündürsə sətirləri bir-bir sıralayan kursorlardan və dövrlərdən (sikllardan) istifadə etməyin. Münasibətli modelinə uyğun olaraq sətirlərə ayrı-ayrılıqda sorğuların verilməsi bəyənilmir, əksinə münasibətli sorğu verilməlidir və nəticədə münasibətli çoxluq alınmalıdır.
Həmçinin yadda saxlamaq lazımdır ki, çoxluqlarda dublikatlar yəni təkrarlanan sətirlər və sütunlar olmamalıdır. T-SQL-də bu qaydaya həmişə əməl olunmur. Məsələn: açarsız bir cədvəl yaratmaq olar. Bu zaman təkrarlanan sətirlər yarada bilərik. Lakin, məsləhətdir ki, cədvəldəki verilənlərin unikallığı qorunsun, bunu unikal və ya əsas açarlarla etmək olar. Ola bilər ki, cədvəldəki sətirlərin unikallığı qorunub, lakin həmin cədvələ verilən sorğunun nəticəsində təkrarlanan sətirlər yaransın. Misal üçün: “Pubs” bazasına belə bir sorğu verək – “müəlliflərin yaşadığı şəhərlərini tapaq”:
USE pubs; GO SELECT city FROM dbo.authors; GO
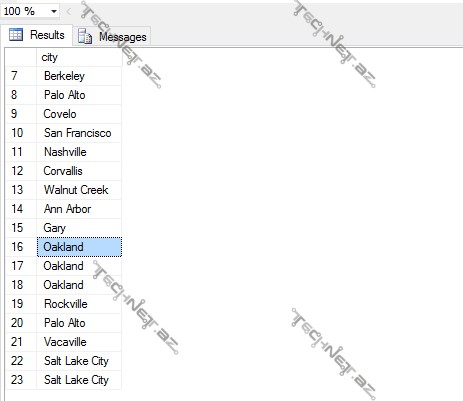
Nəticədə görürük ki, Oakland və Salt Lake City şəhərləri təkrarlanır. Əslində biz nəticədə şəhərlər çoxluğunu aldıq. Yadımıza salaq: çoxluqlar nəzəriyyəsinə görə təkrarlanan sətirlər olmamalıdır. Deməli, biz sorğumuzu münasibətli modelinə uyğunlaşdırmaq üçün nə etməliyik? Sadəcə olaraq alınan nəticədə təkrarlanan sətriləri başqa sözlə dublikatları istisna etməliyik. Bunu etmək üçün T-SQL də DİSTİNCT operatoru vardır. Gəlin sorğumuzu relational, münasibətli modelinə uyğun düzədək:
USE pubs; GO SELECT DISTINCT city FROM dbo.authors; GO
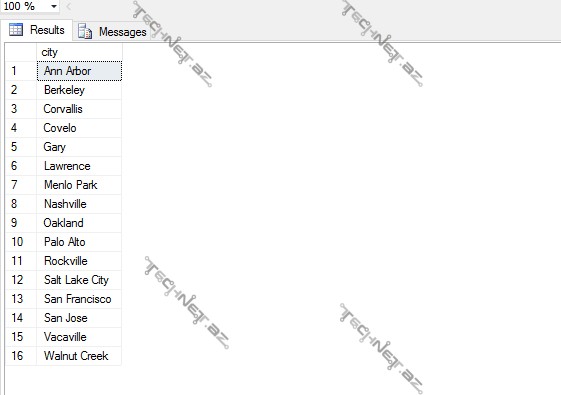
Nəticədə görürük ki, təkrarlanan şəhərlər yoxudur və artıq bizim sorğumuz tam olaraq münasibətli modelinin tələblərinə cavab verir.
Həmçinin qeyd etmişdik ki, çoxluq nəzəriyyəsinə əsasən çoxluqda sətirlərin və sütunların nizamlığı tələb olunmur. Yəni sətirlər və sütunlar istənilən ardıcıllıqla düzülə bilər. Həmçinin sorğunun nəticəsində də sətirlərin ardıcıllığı önəmli deyil. Misal üçün “Pubs” bazasına belə bir sorğu verək – “bütün müəlliflərin adlarını tapaq”:
USE pubs; GO SELECT au_fname FROM dbo.authors; GO
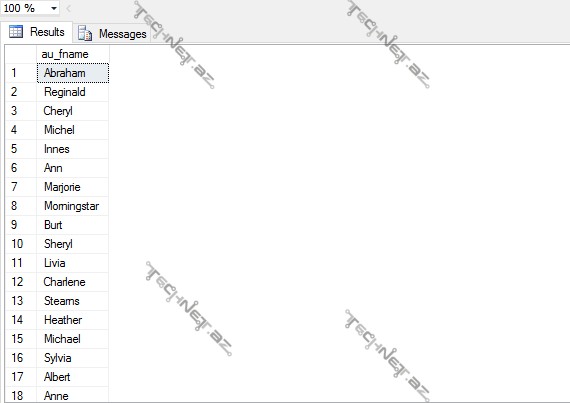
Nəticədə görürük ki, adlar düzülüşündə ardıcıllıq yoxdur. Lakin T-SQL də imkan vardır ki, sətirlər müəyyən ardıcıllıqla düzülsün. Məsələn: biz istəyirik ki, nəticədə adlar ardıcıllıqla düzülsün. Adlar adətən əlifba qaydasında ardıcıllıqla düzmək olar. Bunu ORDER BY şərti vasitəsilə etmək olar. Lakin bu zaman sorğunun nəticəsi münasibətli modelinə uyğun gəlməyəcək. Və burada bizə aydın olur ki, niyə görə ORDER BY şərti həmişə sorğunun sonunda yazılır və ən sonda icra olunur. Bu bir növ əlavə imkan deməkdir və münasibətli (ralatinonal) modelinə aidiyyəti yoxdur. Sorğunu yenidən yazaq:
USE pubs; GO SELECT au_fname FROM dbo.authors ORDER BY au_fname; GO
Nəticədə görürük ki, axtardığımız adlar əlifba sırası ilə düzülüb. Lakin yaddan çıxarmayın ki, bu nəticə münasibətli (ralational) deyil və buna görə də sorğunun icrasını gecikdirə bilər.
Növbəti dərsimizdə görüşənədək.
Diqqətinizə görə təşəkkür edirəm.


