Sinifləşdirmə modellərini qiymətləndirmə ölçülərinin izahı və scikit-learn kitabxanası ilə hesablanması (kredit kartlarının istifadəsində saxtakarlıqların araşdırılması nümunəsində, Python dilində kodlarla)
Giriş
Maşın öyrənməsinin müəllimlə öyrənmə növündən istifadə etməklə hazırlanan sinifləşdirmə modellərinin qiymətləndirilməsi üçün fərqli meyarlar (ing. evaluation metrics) mövcuddur. Giriş üçün qısaca deyim ki, “classification” məsələsi giriş verilənləri (ing. input values) verilən obyektin sinfinin tanınması üçün model qurmaqla həll olunur, bu modelə müəyyən bir obyektin verilənləri verildikdə onun nə tip bir obyekt olması, nə olması, yəni sinfi müəyyən olunur. Məsələn, əlyazma bir hərf şəkli verilir, onun hansı hərfin şəkli olduğu aydınlaşdırılır. Bu barədə daha uzun danışmağa ehtiyac duymuram, bundan əvvəl yazdığım “blog post”-da maşın öyrənməsinin növləri barədə izahat vermiş, nümunələrlə təsvir etmişdim.
Fərz edək ki, sinifləşdirmə məsələsini həll etmək üçün əlimizdə dataset var, biz müəyyən ön – aprior biliklər və hesablama müddətinə qoyulan tələblər əsasında istifadə edə biləcəyimiz bir neçə model tipi (məs., K Nearest Neighbours və Decision Tree) müəyyən etmişik. Bu modellərdən hansını seçəcəyimizi bilmək üçün fərqli ölçülər var. Onlardan ən trivial olanı, ilk ağla gələni “accuracy” adlanır.
“Accuracy” adlanan meyarı izah edə bilmək üçün bu “blog post”-da baxdığımız illustrativ məsələyə giriş vermək məqsədəuyğundur. “Kaggle”-da kredit kartıyla ödəniş tarixçələri – köçürmənin detalları və köçürmənin oğurluq kartla olunub-olunmadığı, başqa sözlə saxtakarlıq (ing. fraud) olub-olmadığı olan bir dataset var. Biz elə bir “classification” modeli qurmalıyıq ki, yeni bir pul köçürməsi olduqda o köçürmənin verilənləri əsasında bizə bu pul köçürməsinin saxtakarlıq (ing. fraud) olub-olmadığını desin. Yəni biz “credit card fraud detection” üçün bir “binary classifier” (ikisinifli tanıma modeli) qurmalıyıq. Dataset pul köçürməsinin saxtakarlıq olub-olmadığını bildirən sütun da daxil olmaqla 8 sütunlu, 1 milyon sətrli .csv faylı şəklində verilir. Pul köçürməsinin verilənləri 7 sütunda təsvir olunub, bu sütunları hər biri köçürmənin bir əlamətidir, həmin xarakteristikalardan bəziləri aşağıda qeyd olunub:
- pul köçürməsinin olduğu yerdən kart sahibinin evə qədər olan məsafə,
- pul köçürməsinin olduğu yerdən axırıncı pul köçürməsinin olduğu yerə qədər olan məsafə,
- bu vaxta qədərki ödəniş məbləğlərini sıralasaq, sırada ortada dayanan qiymətə (ing. median) cari köçürülən məbləğin nisbəti
- köçürmənin onlayn olub-olmaması və s.
Proses belə gedir: Əvvəla “data”-mızı anlayırıq, təmizləyirik, sonra lazım olsa, yenə anlayırıq. Sonra dataseti “training set” və “test set” olmaqla iki yerə bölürük, modeli “training set”-lə öyrədib, digər “set”-lə sınaqdan keçiririk. Yəni bu “blog post”-da danışılan “metric”-ləri “test set” üzərində əldə edirik.
Mündəricat
1. Meyarların izahatı
1.1. Accuracy
1.2. True Positive, True Negative, False Positive, False Negative
1.3. Precision
1.4. Recall
1.5. F1 score
1.6. Precision-Recall əyrisi (Precision-Recall Curve)
1.7. ROC – Receiver Operating Characteristics əyrisi
1.8. Area Under Curve
1.9. Son nəzəri qeydlər
2. İllüstrativ nümunə
2.1. Verilənlərə baxış (ing. exploratory analysis)
2.2. Modelləşdirmə
2.3. Nəticələrin təhlili
Qeyd: Burada yazılanları aşağıda qeyd etdiyim PDF-də də oxuya bilərsiniz.
Meyarların izahatı
Accuracy
“Accuracy” – doğru tanınma tezliyidir. Başqa sözlə, modelin köməyi ilə a dəfə sinifləşdirmə aparsaq, bunlardan b dəfəsi doğru çıxsa, onda “accuracy” b/a kimi hesablanacaq. Bütün proqnozlar doğru olduqda, b=a olur, beləcə accuracy=1 olur. Heç bir proqnoz doğru olmadıqda, yəni bütün proqnozlar yanlış olduqda, yəni b=0 olduqda accuracy=0 olur.
Amma “accuracy”-nin yüksək qiymət alması modelin əla olması demək deyil. Tutaq ki, ağ ciyər təsvirləri əsasında xərçəng xəstəliyinin diaqnozunu verən bir model qururuq və model yüksək “accuracy” verir, yəni tanıdıqlarının çoxunu doğru tanıyır. Amma burada iki cür yanlış tanıma var: Bir, realda xəstə olmayıb da modelin xəstə dedikləri var, bir də realda xəstə olub da “xəstə deyil” çıxanlar var. Ola bilsin, model tanıdıqlarının əksəriyyətini doğru tanıyır amma, əsas diqqətini realda xəstə olanların hamısına xəstə demək, aşkarlamaq əvəzinə xəstə olmayanların əksəriyyətinə “xəstə deyil” deməyə kökləyib. Amma bir çox hallarda bu yanlışdır! Xəstə olan adama “xəstə deyilsən, rahat ol” deyib, adamı böyük təhlükəyə atmaq əvəzinə, xəstə olmayan adamlara səhvən “xəstəsən” demək, adətən, daha yaxşıdır. Hansı ki, “accuracy” ilə modelin performansını bu nöqteyi-nəzərdən dəyərləndirmək olmur. Yəni, “accuracy” hər şey deyil.
True Positive, True Negative, False Positive, False Negative
Davam etmək üçün həll olunan məsələdə siniflərdən birinə “positive”, digərinə “negative” deyək. Saxtakarlıqların aşkarlanmasında saxtakarlıq halının olması “positive”, olmaması “negative”-dir. Və ya adamın xəstə olub-olmadığını deyən model qurduqda, modelin müəyyən bir adamın xəstə olduğunu deməsi “positive”, xəstə olmadığını deməsi “negative” proqnozlaşdırmadır. Modelin “bu köçürmə saxtakarlıqdır” deməsi, yəni “positive” verdiyi proqnoz, həmin köçürmənin həqiqətdə saxtakarlıq olub-olmamasından asılı olaraq doğru (ing. true) və ya yanlış (ing. false) ola bilər. O cümlədən “negative” proqnoz da “true” və ya “false” ola bilər. Deməli, modelin “test set”-dəki hər nümunə üçün proqnozu aşağıdakılardan biri kimi nəticələnir:
- True Positive (TP) – Model pozitiv diaqnoz verib və proqnoz doğrudur. Bizim nümunəmizdə model pul köçürməsini saxtakarlıq adlandırıb və həqiqətən də həmin köçürmə saxtakarlıqdır.
- True Negative (TN) – Model neqativ diaqnoz verib və proqnoz doğrudur. Bizim nümunəmizdə model pul köçürməsini qanuni adlandırıb və həmin köçürmə həqiqətən də saxtakarlıq deyil.
- False Positive (FP) – Model pozitiv diaqnoz verib, proqnoz yanlışdır. Bizim nümunəmizdə model pul köçürməsini saxtakarlıq adlandırıb, ancaq pu köçürməsini kartın əsl sahibi edib. Başqa sözlə, əslində pul köçürməsi saxtakarlıq deyilmiş, model pul köçürənə “şər” atıb.
- False Negative (FN) – Model neqativ diaqnoz verib, proqnoz yanlışdır. Bizim nümunəmizdə model pul köçürməsini qanuni adlandırıb, amma həmin köçürmə oğurlanmış kartla edilib. Başqa sözlə, əslində pul köçürməsi saxtakarlıq imiş, model “gözdən qaçırıb”.
“Test set”-dəki hər müşahidənin giriş dəyərlərini modelə verib, modelin proqnozlaşdırdığı nəticə ilə bazadadakı real nəticəni müqayisə etməklə bu müşahidənin tanınmasının TP, TN, FP, FN-dən hansı olduğunu təyin edə bilərik. Sonra da “test set”-də neçə ədəd TP, neçə ədəd TN, neçə ədəd FP və neçə ədəd FN olduğunu taparıq.
Fərz edək ki, TP, TN, FP, FN həmin saylardır, onda “accuracy”-ni aşağıdakı düsturla ifadə etmək olar:
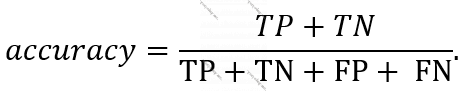
“Accuracy” haqqında danışıb, sonra ona təzədən qayıtmağım çaşdırıcı ola bilər. Lakin izaha birbaşa TP, TN, FP, FN-dən başlasaydım, xüsusən “data science”-a yeni başlayanlar üçün başa düşmək, daha doğrusu, hiss etmək çətin olacaqdı.
Precision
“Accuracy” (“binary classification”-da) hər iki sinfin nəticəsini özündə birləşdirir. Yəni “accuracy” modelin proqnozlarını səlis vermə tezliyidir. “Precision” da bir sinfə uyğun olaraq modelin verdiyi proqnozlardan neçəsinin doğru olmasını özündə ehtiva edir. Başqa sözlə, positive proqnozlaşdırmaların neçəsinin doğru olduğuna bir, neqativ proqnozlaşdırmaların neçəsinin doğru olduğuna başqa bir “precision” qiyməti uyğun gəlir. Amma “accuracy” tanıma dəqiqliyini modelin proqnozunun pozitiv və ya neqativ olmasından asılı olmayaraq verirdi.
Pozitiv proqnoz, bizim nümunədə modelin bu pul köçürməsi saxtakarlıqdır proqnozundakı dəqiqlik – “precision” aşağıdakı düsturla təyin olunur:
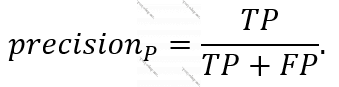
Neqativ proqnoz, bizim nümunədə modelin bu pul köçürməsi saxtakarlıq deyil proqnozundakı dəqiqlik – “precision” aşağıdakı düsturla təyin olunur:
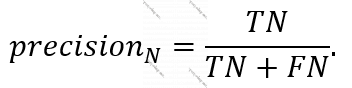
Əlbəttə ki, sadəcə “precision” deyildikdə, adətən, pozitiv proqnozlardakı “precision” nəzərdə tutulur.
Recall
“Recall” da, “precision” kimi hər “class” üçün ayrılıqda təyin olunur. Yəni hər “class”-da, realda pozitiv və neqativ olanlarda ayrı “recall” qiymətləri alınır. “Precision” modelin pozitiv (və ya neqativ) dediklərinin neçəsinin doğru olduğunu nəzərə alırdı, amma “recall” həqiqətən də pozitiv (və ya neqativ) sinifdə olmalı olanların neçəsinin model tərəfindən pozitiv (və ya neqativ) kimi proqnozlaşdırıldığını göstərir.
“Test set”-də saxtakarlıq olan pul köçürmələrindəki “recall” aşağıdakı düsturla təyin olunur:
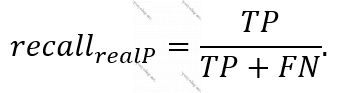
“Test set”-də saxtakarlıq olmayan pul köçürmələrindəki “recall” aşağıdakı düsturla təyin olunur:
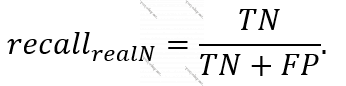
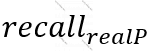 -yə “sensitivity”,
-yə “sensitivity”, ![]() -yə “specificity” də deyilir. Bizim nümunədə modelin həqiqətdə “fraud” olanların neçəsini doğru tanıması “sensitivity”, həqiqətən qanuni olan köçürmələrin neçəsini doğru tanıması isə “specificity” başlığı altında araşdırılır. Xəstəliklərin aşkarlanmasında biz, əlbəttə, diqqətimizi “sensitivity”-yə yönəldirik. Amma “credit card fraud detection” məsələsində bu, şirkətin strategiyasından asılıdır. Ola bilsin, bank müştərilərini yalan yerə narahat eləmək istəmir, yəni istəmir ki, “fraud” olmayan köçürməyə səhvən “fraud” desin. Bu halda onlara neqativ sinifdəki – “fraud” olmayanlardakı “precision” və “recall” maraqlıdır. Yox əgər bank heç cür “credit card fraud”-dan pul itirmək istəmirsə, onda pozitiv sinifdəki – “fraud” olanlardakı “precision” və “recall”-da maraqlıdırlar.
-yə “specificity” də deyilir. Bizim nümunədə modelin həqiqətdə “fraud” olanların neçəsini doğru tanıması “sensitivity”, həqiqətən qanuni olan köçürmələrin neçəsini doğru tanıması isə “specificity” başlığı altında araşdırılır. Xəstəliklərin aşkarlanmasında biz, əlbəttə, diqqətimizi “sensitivity”-yə yönəldirik. Amma “credit card fraud detection” məsələsində bu, şirkətin strategiyasından asılıdır. Ola bilsin, bank müştərilərini yalan yerə narahat eləmək istəmir, yəni istəmir ki, “fraud” olmayan köçürməyə səhvən “fraud” desin. Bu halda onlara neqativ sinifdəki – “fraud” olmayanlardakı “precision” və “recall” maraqlıdır. Yox əgər bank heç cür “credit card fraud”-dan pul itirmək istəmirsə, onda pozitiv sinifdəki – “fraud” olanlardakı “precision” və “recall”-da maraqlıdırlar.
F1 score
Dedik ki, “precision” da, “recall” da hər “class” üçün ayrı-ayrılıqda alınır. “Precision” modelin o sinifdən olduğu dediklərinin dəqiqliyidir, “recall” isə realda həmin sinifdə olanların neçəsini doğru tanındığı. Bu iki meyarı bir meyarda birləşdirmək olar, onu “F1 score” adlandırırlar. Ümumilikdə “precision” və “recall”-un ikisinin də böyük qiymət alması yaxşıdır. “F1 score” bu ikisindən alınır, onun da qiyməti yüksək olsa, yaxşıdır. Ümumilikdə, blog post-da sadalanan bütün meyarlar 0-la 1 arasında qiymət verir, ən pis – 0, ən yaxşı – 1 qiymətidir. Bu, “accuracy”, “precision”-lar, “recall”-lar, “F1 score”-lar üçün eynidir. “Precision” və “recall” hər sinif üçün ayrıca tapıldığına görə onlardan alınan “F1 score” da hər sinif üçün ayrı-ayrılıqda tapılır.
Pozitiv sinif üçün “F1 score” aşağıdakı düsturla təyin olunur:
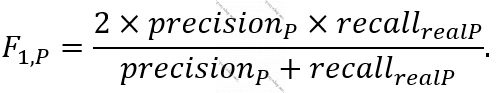
Neqativ sinif üçün “F1 score” aşağıdakı düsturla təyin olunur:
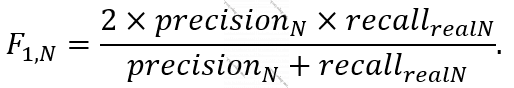
Precision-Recall əyrisi (Precision-Recall Curve)
Model obyektin sinfini proqnozlaşdırdıqda pozitiv sinfə nə dərəcədə məxsus olmasının, bizim məsələdə pul köçürməsinin nə dərəcədə saxtakarlıq (ing. fraud) olmasının ehtimalını qaytarır. Ola bilər ki, model verilmiş pul köçürməsinin “fraud” olmasına 0.51 ehtimalla inansın, o da ola bilər ki, 0.99 ehtimalla inana. Onda biz sərhəd qoya bilərik ki, modelin yalnız 0.8 və ondan böyük ehtimalla inandığı proqnozları doğru sayaq, yəni modelin 0.8-dən aşağı ehtimalla inandıqları proqnozları saymayaq. Bu sərhədə (məs., yuxarıda 0.8 dediyimiz kimi) çoxdan aza doğru qiymətlər versək və hər belə inam sərhədi qiymətində “precision” və “recall” qiymətləri ala bilərik. Belə olduqda aşağıdakı kimi qrafiklər alına bilər:
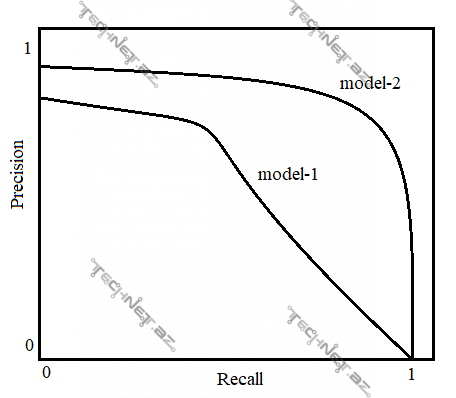
Yuxarıdakı qrafikdən aydın olur ki, “precision-recall” əyrisinə görə “model-2” “model-1”-dən daha yaxşıdır.
Sonda demək olar ki, “precision”-la “recall”-u eyni zamanda nəzərə almaqla qərar vermək üçün “precision-recall curve” “F1 score”-a nəzərən daha informativdir, çünki sadəcə bir inam dərəcəsindənsə (0.5) bir çox inam dərəcələrində nəticə verir. Və əlbəttə ki, bu əyridəki “precision” və “recall” qiymətləri “positive class”-a görə əldə edilənlərdir.
ROC – Receiver Operating Characteristics
Real olaraq pozitiv sinifdə olanlar əsasında aldığımız “recall”-a “sensitivity” demişdik. Real olaraq neqativ sinifdə olanlar əsasında aldığımız “recall”-a isə “specificity” deyirdik. Pozitiv “recall”-a “sensitivity”-dən əlavə “True Positive rate” – də deyirlər. Dərindən baxanda da “sensitivity” TP-lərin realda pozitiv olanlara nisbətidir. Bu da modelin realda pozitiv olan müşahidələrin hansı hissəsini doğru tanıdığı demək idi. Amma bunlardan əlavə “False Positive Rate” (FPR) adlanan başqa bir meyar da var. Burada isə modelin həqiqətdə neqativ olan müşahidələrin neçəsinə səhvən pozitiv dediyi araşdırılır, düsturu aşağıdakı kimidir:
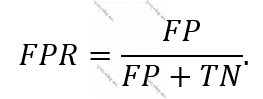
Deməli, modelin həqiqətdə neqativ olanların neçəsinə neqativ dediyinə “specificity” deyirdik, modelin həqiqətdə neqativ olanların neçəsinə səhvən pozitiv dediyinə isə FPR dedik. Düsturlara da baxsaq, sonuncu cümləyə də fikir versək, görərik ki, FPR = 1 – specificity.
Nəticə etibarı ilə FPR az olsa, TPR (pozitiv müşahidələrdəki “recall”) çox olsa, yaxşıdır. Modelin aldığı TPR-ın FPR-dan asılılığı “Receiver Operating Curve” adlanan əyri ilə ifadə olunur.
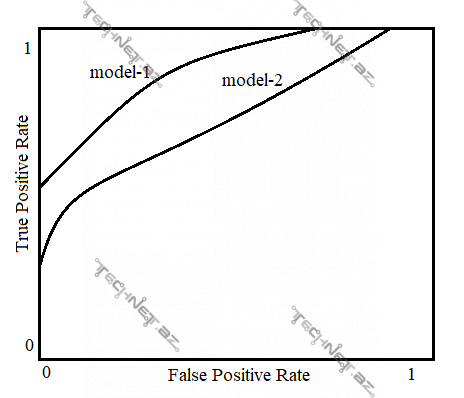
Yuxarıdakı qrafikdə ROC-a görə “model-1” “model-2”-dən daha yaxşı nəticə göstərmişdir, çünki az FPR-da daha çox TPR qiyməti alıb.
Area Under Curve
ROC-un (TPR-in FPR-dən asılılığını ifadə edən əyrinin) altında qalan sahəyə “Area Under Curve” və ya sadəcə AUC deyirlər və nə qədər böyük qiymət alsa, o qədər yaxşıdır. AUC 0-la 1 arasında (0 və 1 də daxil olmaqla) qiymət alır.
Son nəzəri qeydlər
Bu “blog post”-da “accuracy”-dən başqa adı çəkilən bütün meyarların, adətən, “binary classification” istifadəsi və başa düşülməsi daha asandır. Çünki bu meyarlarda pozitiv-neqativ “class” barədəki performans göstəricilərindən istifadə olunur. Amma “multi-class” classification məsələlərində də müəyyən bir “class”-ı “positive” bilib, təhlil aparmaq olar. Hətta hər “class”-ı ayrı-ayrılıqda pozitiv bilib, hər “class” üçün qiymətlər almaq olar. Bundan əlavə hər class üçün bu meyarların qiymətlərini hesabladıqdan sonra orta göstəricini tapmaq da olar.
Ümumilikdə TP, FP, TN, FN qiymətlərini bir “confusion matrix”-də birləşdirmək olur. Tutalım, üç sinifli sinifləşdirmə aparırıq, onda aşağıdakı kimi bir “confusion matrix” alırıq:
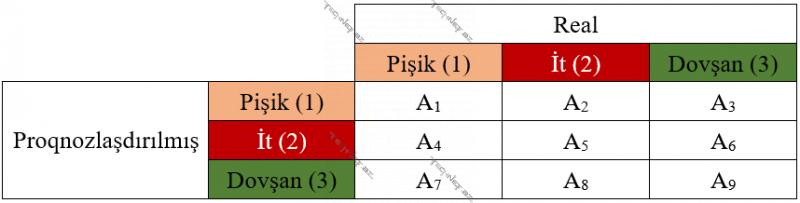
Burada A1,…, A9 müəyyən ədədlərdir. Məsələn, it sinfi üçün TP, FP, TN, FN qiymətlərini almaq məqsədi ilə (hansı ki, bu qiymətlər əsasında, “precision”, “recall” və s. almaq olar) 2-ci sütunla 2-sətrin kəsişməsindəki ədədləri – A2, A5, A8, A4, A6 istifadə etmək olar.
İllüstrativ nümunə
Bütün kodlara Kaggle-da və Githubda baxa bilərsiniz.
Verilənlərə baxış (ing. exploratory analysis)
Əvvəla lazım olan kitabxanaları daxil edirik:
# Import libraries
import os, random, sklearn
import pandas as pd
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from tensorflow.keras.utils import to_categorical
from sklearn.svm import SVC
from sklearn.utils import class_weight
from sklearn import metrics
from sklearn.metrics import roc_curve, auc, precision_recall_curve
import tensorflow as tf
from tensorflow import keras
from matplotlib import pyplot as plt
import numpy as np
from tensorflow.keras import datasets, layers, models, losses
from tensorflow.keras import models
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import EarlyStopping
import seaborn as sns
Bəzi ümumi xarakteristikaları dəqiqləşdiririk:
# Some Basic Characteristics
SEED = 42
TEST_SIZE_DATASET__SIZE_RATIO = 0.2
random.seed = SEED
tf.random.set_seed(SEED)
DATASET_PATH = 'datasets/creditcardfraud/card_transdata.csv'
OUTPUT_PATH = 'output/'
CLASS_NAMES = ['Valid', 'Fraud']
MODEL_NAME_ANN = 'ANN'
MODEL_NAME_XGB = 'XGBClassifier'
MODEL_NAME_XGB10 = 'XGBClassifier - 10'
if not os.path.exists(OUTPUT_PATH):
os.makedirs(OUTPUT_PATH)
# Define sample weights according to the class data available (class imbalance)
class_weights = class_weight.compute_sample_weight(
class_weight='balanced',
y=y_train
)
Dataseti oxuyuruq:
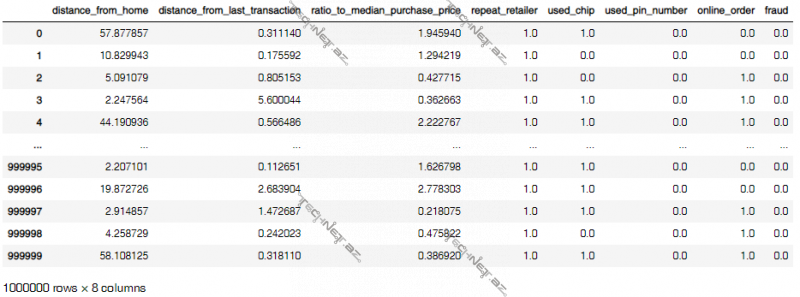
# Read dataset
df = pd.read_csv(DATASET_PATH)
df
Boş qalan xanaların olub-olmadığını aydınlaşdırırıq:
# NA values counts
df.isnull().sum()
distance_from_home 0
distance_from_last_transaction 0
ratio_to_median_purchase_price 0
repeat_retailer 0
used_chip 0
used_pin_number 0
online_order 0
fraud 0
dtype: int64
Gördüyünüz kimi heç bir sütun üzrə boş xana yoxdur.
Dataset haqqında digər xarakteristikalara belə də nəzər sala bilirik:
# Look through columns and NA values statistics
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000000 entries, 0 to 999999
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 distance_from_home 1000000 non-null float64
1 distance_from_last_transaction 1000000 non-null float64
2 ratio_to_median_purchase_price 1000000 non-null float64
3 repeat_retailer 1000000 non-null float64
4 used_chip 1000000 non-null float64
5 used_pin_number 1000000 non-null float64
6 online_order 1000000 non-null float64
7 fraud 1000000 non-null float64
dtypes: float64(8)
memory usage: 61.0 MB
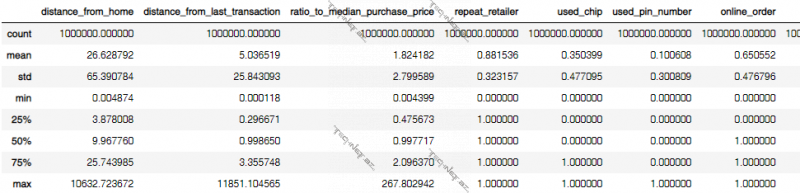
Datasetdəki sütunlar üzrə statistik göstəricilər əldə olunur. Məsələn, “distance_from_home” sütunu üzrə ədədlərin 25%-i 3.878008, 50%-i 9.967760, 75%-i 25.743985-ə qədər qiymətlər alıb.
# Show statistical characteristics
df.describe()
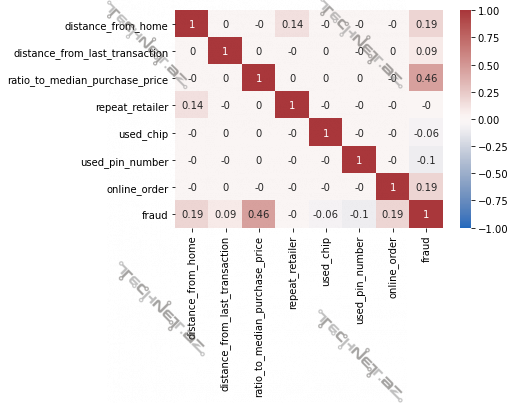
Sütunların cüt-cüt xətti əlaqələri yoxlanılır. Gördüyünüz kimi bu vaxta qədərki ödəniş məbləğlərini sıralasaq, sırada ortada dayanan qiymətə (ing. median) cari köçürülən məbləğin nisbətini bildirən “ratio_to_median_purchase_price” sütunu ilə saxtakarlıq olub-olmama arasındakı xətti əlaqə digərlərinə nəzərdə daha yüksəkdir. Buna “correlation matrix” deyilir.
# Visualize linear relationships between features
matrix = df.corr().round(2)
sns.heatmap(matrix, annot=True, vmax=1, vmin=-1, center=0, cmap='vlag')
plt.savefig(os.path.join(OUTPUT_PATH, 'Corr-CreditCardFraudDetection.png'), dpi=300)
plt.show()
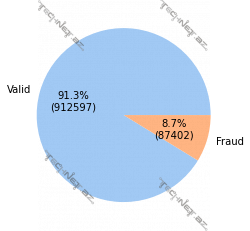
Köçürülmədə saxtakarlıq olan və olmayan müşahidələrin sayları qeyd olunur. Gördüyünüz kimi saxtakarlıq olan müşahidələrin sayı saxtakarlıq olmayan müşahidələrin sayından çoxdur.
# Visualize class imbalance/data availablity
def func(pct, allvalues):
absolute = int(pct / 100.0 * np.sum(allvalues))
return "{:.1f}%\n({:d})".format(pct, absolute)
colors = sns.color_palette('pastel')[0:5]
data_pie = list(df.fraud.value_counts())
#create pie chart
plt.pie(data_pie, labels = ['Valid', 'Fraud'], colors = colors,
autopct = lambda pct: func(pct, data_pie))
plt.savefig(os.path.join(OUTPUT_PATH, 'Class Imbalance Pie-CreditCardFraudDetection.png'), dpi=300)
plt.show()
Dataseti giriş sütunları və çıxış sutununa, yəni X və Y-ə bölək.
# Specify features and target
X = df[df.columns[0:-1]].to_numpy()
Y = df[df.columns[-1]].to_numpy()
# Split dataset into training and test sets
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=TEST_SIZE_DATASET__SIZE_RATIO, random_state=SEED)
print('Train:', x_train.shape)
print('Test:', x_test.shape)
Train: (800000, 7)
Test: (200000, 7)
Modelləşdirmə
Süni Neyron Şəbəkənin lazımi hiperparametrləri daxil edilir:
# Specify hyperparameters for ANN and CNN
EPOCHS = 200
callback = EarlyStopping(monitor='loss', min_delta=0.01, patience=5)
POOL_CHOICE = layers.AveragePooling2D
PADDING_CHOICE = 'valid'
KERNEL_SIZE = (5,5)
POOL_SIZE = (2,2)
ACT_FUNC = keras.activations.relu
OPT = keras.optimizers.Adam
LOSS_FUNC = keras.losses.categorical_crossentropy
METRICS = ['accuracy',
'mse', 'mae']
Modellər qurulur: 1 süni neyron şəbəkə, birində 10, digərində 100 qərar ağacı (ing. Decision Tree) olmaqla 2 ayrı XGBoostClassifier. “XGBoostClassifier”-in susmaya görə, “default” olaraq 100 model qurulur.
# Define two XGBClassifiers
model_xgb = XGBClassifier()
model_xgb10 = XGBClassifier(n_estimators = 10)
# Define structure of the ANN with structure 128-256-512-512-512-256-128-64-32-2
keras.backend.clear_session()
model_ANN = models.Sequential(name = MODEL_NAME_ANN)
model_ANN.add(layers.Dense(128, input_shape = (x_train.shape[1],), activation=ACT_FUNC))
model_ANN.add(layers.Dense(256, activation=ACT_FUNC))
model_ANN.add(layers.Dense(512, activation=ACT_FUNC))
model_ANN.add(layers.Dense(512, activation=ACT_FUNC))
model_ANN.add(layers.Dense(512, activation=ACT_FUNC))
model_ANN.add(layers.Dense(256, activation=ACT_FUNC))
model_ANN.add(layers.Dense(128, activation=ACT_FUNC))
model_ANN.add(layers.Dense(64, activation=ACT_FUNC))
model_ANN.add(layers.Dense(32, activation=ACT_FUNC))
model_ANN.add(layers.Dense(2, activation='softmax'))
model_ANN.compile(optimizer = OPT(), loss = LOSS_FUNC, metrics = METRICS)
model_ANN.summary()
Model: "ANN"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 128) 1024
_________________________________________________________________
dense_1 (Dense) (None, 256) 33024
_________________________________________________________________
dense_2 (Dense) (None, 512) 131584
_________________________________________________________________
dense_3 (Dense) (None, 512) 262656
_________________________________________________________________
dense_4 (Dense) (None, 512) 262656
_________________________________________________________________
dense_5 (Dense) (None, 256) 131328
_________________________________________________________________
dense_6 (Dense) (None, 128) 32896
_________________________________________________________________
dense_7 (Dense) (None, 64) 8256
_________________________________________________________________
dense_8 (Dense) (None, 32) 2080
_________________________________________________________________
dense_9 (Dense) (None, 2) 66
=================================================================
Total params: 865,570
Trainable params: 865,570
Non-trainable params: 0
_________________________________________________________________
Süni neyron şəbəkənin öyrədilməsi:
# Training ANN model
training_history_ANN = model_ANN.fit(x_train, to_categorical(y_train), epochs = EPOCHS, shuffle = True,
callbacks=[callback], verbose=1,
class_weight={0:1/sum(y_train == 0),1:1/sum(y_train == 1)})
Epoch 1/200
25000/25000 [==============================] - 276s 11ms/step - loss: 2.9642e-07 - accuracy: 0.9375 - mse: 0.0452 - mae: 0.0699
Epoch 2/200
25000/25000 [==============================] - 289s 12ms/step - loss: 1.3921e-07 - accuracy: 0.9729 - mse: 0.0206 - mae: 0.0293
Epoch 3/200
25000/25000 [==============================] - 304s 12ms/step - loss: 1.0572e-07 - accuracy: 0.9797 - mse: 0.0155 - mae: 0.0222
Epoch 4/200
25000/25000 [==============================] - 262s 10ms/step - loss: 8.7523e-08 - accuracy: 0.9838 - mse: 0.0126 - mae: 0.0180
Epoch 5/200
25000/25000 [==============================] - 290s 12ms/step - loss: 7.1982e-08 - accuracy: 0.9863 - mse: 0.0104 - mae: 0.0149
Epoch 6/200
25000/25000 [==============================] - 291s 12ms/step - loss: 6.4380e-08 - accuracy: 0.9879 - mse: 0.0092 - mae: 0.0134
Süni neyron şəbəkənin öyrədilməsinin detallı nəticələri:
"""
METHOD: Show metrics obtained during each epoch in training of ANN model
The metrics are the following:
Loss - Categorical Crossentropy
Accuracy - rate of the accurate/true predictions over all predictions
MSE - Mean Squared Error
MAE - Mean Absolute Error
"""
def plot_training_history(training_history, file_name = None):
loss_history = training_history.history['loss']
acc_history = training_history.history['accuracy']
mse_history = training_history.history['mse']
mae_history = training_history.history['mae']
# Define plot size, approximately 1024x1024 pixels
dpi = 300
num_of_pixels = 1024
num_of_inches = num_of_pixels / dpi
cm = num_of_inches * 2.54
plt.gcf().set_dpi(dpi)
fig = plt.figure(figsize=(cm,cm))
plt.subplots_adjust(hspace=0.3)
axs11 = fig.add_subplot(2,2,1)
axs12 = fig.add_subplot(2,2,2)
axs21 = fig.add_subplot(2,2,3)
axs22 = fig.add_subplot(2,2,4)
fig.suptitle('Training Metrics - ' + file_name if file_name is not None else '')
x_ticks = np.arange(1, len(loss_history), 2)
for axs in (axs11, axs12, axs21, axs22):
axs.set_xlabel('epochs')
axs.set_xticks(x_ticks)
axs11.plot(loss_history)
axs11.set_title('Loss')
axs12.plot(acc_history)
axs12.set_title('Accuracy')
axs21.plot(mse_history)
axs21.set_title('MSE')
axs22.plot(mae_history)
axs22.set_title('MAE')
plt.show()
# Save the figure as an image if specified
if file_name is not None:
fig.savefig(os.path.join(OUTPUT_PATH, 'Training Metrics - ' + file_name + '.jpg'))
plot_training_history(training_history_ANN, file_name='CreditCardFraud')
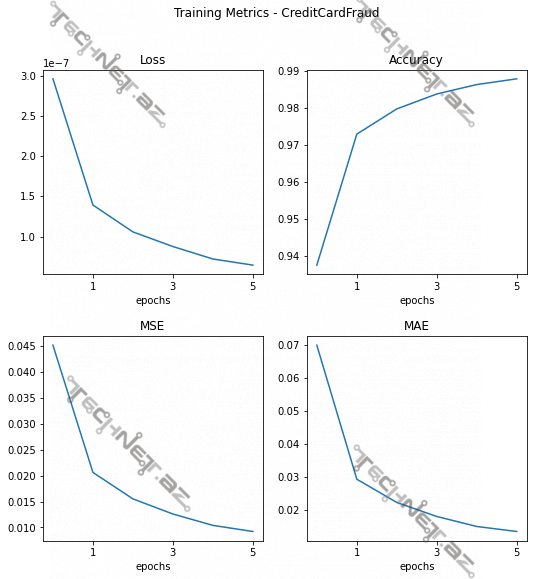
“XGBoostClassifier”-lər öyrədilir:
print('Training XGB ...')
model_xgb.fit(x_train, y_train, sample_weight=class_weights)
print('Training XGB with 10 Trees...')
model_xgb10.fit(x_train, y_train, sample_weight=class_weights)
Nəticələrin təhlili
“Test set” üzərində performans göstəriciləri hesablanır. Əvvəla “confusion matrix” verilir, sonra həm pozitiv (Fraud), həm də neqativ sinfə görə “precision”, “recall”, “F1 score” qiymətləri verilir. Burada “Valid” dedikdə “Fraud” olmayan köçürmələr nəzərdə tutulub.
"""
METHOD: Show evaluation metrics over TEST data & estimate confusion matrix
The metrics are the following: Precision, Recall, F1 Score, Support.
"""
def conf_matrix_and_classification_report(y_true, y_pred, num_of_classes = 10, class_names = None):
if class_names is None:
class_names = [str(i) for i in range(num_of_classes)]
conf_matrix = sklearn.metrics.confusion_matrix(y_true, y_pred)
for i in range(len(conf_matrix)):
print(class_names[i] + ':', conf_matrix[i])
print('-----------------------------------------------------')
# Print the precision and recall, among other metrics
print(sklearn.metrics.classification_report(y_true, y_pred, target_names = class_names)) # output_dict=True, for not rounding
print(f'Detailed Training Results of {MODEL_NAME_ANN} model')
y_pred_1hot_ann = model_ANN.predict(x_test)
y_pred_ann = np.argmax(y_pred_1hot_ann, axis = 1)
conf_matrix_and_classification_report(y_test, y_pred_ann, class_names=CLASS_NAMES)
print()
print(f'Detailed Training Results of {MODEL_NAME_XGB10} model')
y_pred_1hot_xgb10 = model_xgb10.predict_proba(x_test)
y_pred_xgb10 = np.argmax(y_pred_1hot_xgb10, axis = 1)
conf_matrix_and_classification_report(y_test, y_pred_xgb10, class_names=CLASS_NAMES)
print()
print(f'Detailed Training Results of {MODEL_NAME_XGB} model')
y_pred_1hot_xgb = model_xgb.predict_proba(x_test)
y_pred_xgb = np.argmax(y_pred_1hot_xgb, axis = 1)
conf_matrix_and_classification_report(y_test, y_pred_xgb, class_names=CLASS_NAMES)
Detailed Training Results of ANN model
Valid: [175996 6561]
Fraud: [ 4 17439]
—————————————————–
precision recall f1-score support
Valid 1.00 0.96 0.98 182557
Fraud 0.73 1.00 0.84 17443
accuracy 0.97 200000
macro avg 0.86 0.98 0.91 200000
weighted avg 0.98 0.97 0.97 200000
Detailed Training Results of XGBClassifier – 10 model
Valid: [182537 20]
Fraud: [ 2 17441]
—————————————————–
precision recall f1-score support
Valid 1.00 1.00 1.00 182557
Fraud 1.00 1.00 1.00 17443
accuracy 1.00 200000
macro avg 1.00 1.00 1.00 200000
weighted avg 1.00 1.00 1.00 200000
Detailed Training Results of XGBClassifier model
Valid: [182556 1]
Fraud: [ 2 17441]
—————————————————–
precision recall f1-score support
Valid 1.00 1.00 1.00 182557
Fraud 1.00 1.00 1.00 17443
accuracy 1.00 200000
macro avg 1.00 1.00 1.00 200000
weighted avg 1.00 1.00 1.00 200000
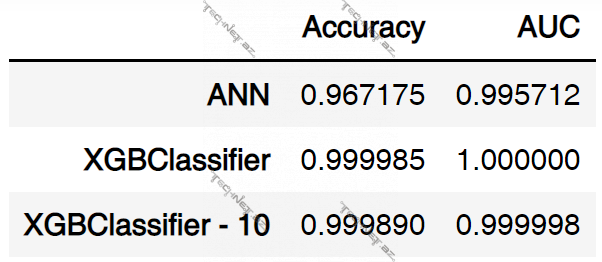
Accuracy və AUC göstəriciləri alınır:
# Calculate some metrics: Area Under Curve, Accuracy
# Prepare metrics for Receiver Operating Characteristics and Precision on Recall curves
y_test_1hot = to_categorical(y_test)
y_test_prob = y_test_1hot[:,1]
y_pred_prob_ann, y_pred_prob_xgb10, y_pred_prob_xgb = y_pred_1hot_ann[:,1], y_pred_1hot_xgb10[:,1], y_pred_1hot_xgb[:,1]
fpr_ann, tpr_ann, thresholds_ann = roc_curve(y_test_prob, y_pred_prob_ann)
fpr_xgb10, tpr_xgb10, thresholds_xgb10 = roc_curve(y_test_prob, y_pred_prob_xgb10)
fpr_xgb, tpr_xgb, thresholds_xgb = roc_curve(y_test_prob, y_pred_prob_xgb)
precision_ann, recall_ann, thresholds_ann = precision_recall_curve(y_test_prob, y_pred_prob_ann)
precision_xgb10, recall_xgb10, thresholds_xgb10 = precision_recall_curve(y_test_prob, y_pred_prob_xgb10)
precision_xgb, recall_xgb, thresholds_xgb = precision_recall_curve(y_test_prob, y_pred_prob_xgb)
auc_ann = auc(fpr_ann, tpr_ann)
auc_xgb10 = auc(fpr_xgb10, tpr_xgb10)
auc_xgb = auc(fpr_xgb, tpr_xgb)
acc_ann = metrics.accuracy_score(y_test, y_pred_ann)
acc_xgb10 = metrics.accuracy_score(y_test, y_pred_xgb10)
acc_xgb = metrics.accuracy_score(y_test, y_pred_xgb)
# Show ACC and AUC for models
row1 = [acc_ann, auc_ann]
row2 = [acc_xgb, auc_xgb]
row3 = [acc_xgb10, auc_xgb10]
df_metrics = pd.DataFrame(np.array([row1, row2, row3]), columns=['Accuracy', 'AUC'])
df_metrics.index = [MODEL_NAME_ANN, MODEL_NAME_XGB, MODEL_NAME_XGB10]
df_metrics
“ROC” və “Precision on Recall” əyriləri çəkilir. Qeyd: 10 ağaclı XGBoostClassifier ilə digər 100 ağaclı XGBoostClassifier arasındakı fərq çox olmadığından 10 ağaclı olanı daxil edilməyib.
class LengthsDoNotMatchException(Exception):
def __init__(self, length1, length2):
message = f'Lengths of arrays do not match: {length1} vs {length2}'
super().__init__(message)
"""
METHOD: Show metrics obtained In Testing WITH COMPARISONS OVER DIFFERENT MODELS
Curves - ROC and Precision on Recall
Metrics - AUC
"""
def plot_roc_pr_curve(roc_results, pr_results, model_names, file_name = None):
if not (len(roc_results) == len(pr_results) and len(pr_results) == len(model_names)):
raise LengthsDoNotMatchException(len(training_histories), len(model_names))
# Define plot size, approximately 1024x1024 pixels
dpi = 300
num_of_pixels = 1024
num_of_inches = num_of_pixels / dpi
cm = num_of_inches * 2.54
plt.gcf().set_dpi(dpi)
fig = plt.figure(figsize=(cm,cm))
plt.subplots_adjust(hspace=0.3)
axs11 = fig.add_subplot(2,1,1)
axs21 = fig.add_subplot(2,1,2)
fig.suptitle('Training Metrics - ' + file_name if file_name is not None else '')
axs11.set_xlabel('False Positive Rate')
axs11.set_ylabel('True Positive Rate')
axs21.set_xlabel('Recall')
axs21.set_ylabel('Precision')
for i in range(len(roc_results)):
axs11.plot(roc_results[i][0], roc_results[i][1], label = model_names[i])
axs21.plot(pr_results[i][0], pr_results[i][1], label = model_names[i][:model_names[i].find('(')])
axs11.set_title('Receiver Operating Characteristics')
axs21.set_title('Precision on Recall')
axs11.legend()
axs21.legend()
plt.show()
# Save the figure as an image if specified
if file_name is not None:
fig.savefig(os.path.join(OUTPUT_PATH, 'Training Metrics - ' + file_name + '.jpg'))
# Plot ROC and Precision on Recall curves
roc_results_ann_xgb = [(fpr_ann, tpr_ann), (fpr_xgb, tpr_xgb)]
pr_results_ann_xgb = [(recall_ann, precision_ann), (recall_xgb, precision_xgb)]
plot_roc_pr_curve(roc_results=roc_results_ann_xgb,
pr_results=pr_results_ann_xgb,
model_names=[MODEL_NAME_ANN + f' (AUC: {round(auc_ann, 4)})', MODEL_NAME_XGB + f' (AUC: {round(auc_xgb, 4)})'],
file_name='ANN-XGB-CredictCardFraudDetection')

Modellər yadda saxlanıla bilər:
# Save models
PROBLEM_NAME = 'CreditCardFraudDetection'
model_xgb.save_model(os.path.join(OUTPUT_PATH, f"model_xgb100-{PROBLEM_NAME}.json"))
model_xgb10.save_model(os.path.join(OUTPUT_PATH, f"model_xgb10-{PROBLEM_NAME}.json"))
model_ANN.save(os.path.join(OUTPUT_PATH, f"model_ann-{PROBLEM_NAME}"))
İstinadlar
- https://www.kaggle.com/datasets/dhanushnarayananr/credit-card-fraud
- https://machinelearningmastery.com/tour-of-evaluation-metrics-for-imbalanced-classification/
- https://scikit-learn.org/stable/auto_examples/model_selection/plot_precision_recall.html
- https://towardsdatascience.com/multi-class-metrics-made-simple-part-i-precision-and-recall-9250280bddc2
- https://xgboost.readthedocs.io/en/stable/python/python_api.html


