Azure Platformasında Təhlükəsizlik konseptləri -3

Əlçatanlıq (Availability)
Cloud mühitində servis yerləşdirən hər bir biznes-müştəri və yaxud sadə istifadəçi üçün, Availability maksimal dərəcədə vacib şərtdir. Microsoft Cloud Platforması funksionallığın saxlanması üçün imkanları ehtiyac olandan artıq təklif edir. Bununla müştərinin məlumatlarını maksimal dərəcədə əlçatan edir.Storage Əlçatanlığının təmin edilməsinin əsas mexanizmi replikasiyadır. Bunlar LRS, GRS, ZRS və RA-GRS-dir. Bu mexanizmlərin bəziləri ilə yaxından tanış olaq:
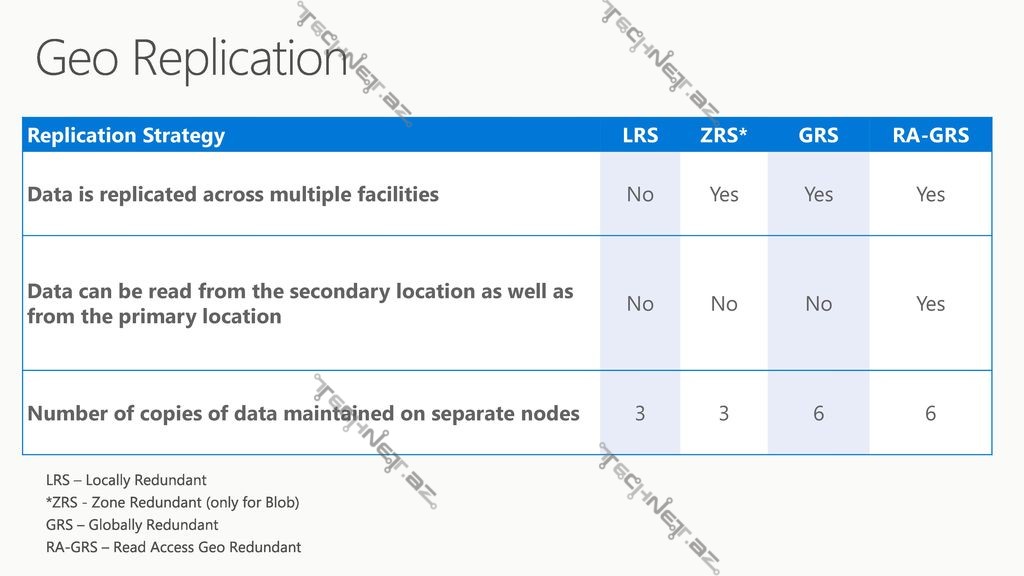
- Locally Redundant Storage (LRS) bir coğrafik lokasiya çərçivəsində yüksək dərəcədə əlçatanlıq və dayanıqlıq təklif edən storage-dir. Bu platforma Primary coğrafi lokasiyada, hər məlumat elementinin 3 replikasını saxlayır. Beləliklə, ümumi xarakterli uğursuzluq zamanı (məsələn: Disk, Node və sairə fiziki elementlərin sıradan çıxması halında) məlumat bərpasına zəmanət verir. Qeyd etmək lazımdır ki, bu cürə qəza hallarında Əlçatanlıq pozulmur, hətta minimal downtime olmur.
Ümumilikdə isə Storage-də baş verən bütün yazılma əməliyyatları sinxron olaraq 3 replikada və 3 müxtəlif fault domain-də yerinə yetirilir. Yalnız bu əməliyyatlar tam sona çatdıqdan sonra tranzaksiyanın uğurla qurtarmağı haqqında kod qayıdır.
Hər hansı bir səbəbən lokal storage tam dolarsa və ya nüsxə məlumatları yerləşən Data Mərkəz hansısa səbəbdən tamamilə xarab olarsa, Microsoft müştəri ilə əlaqə saxlayıb məlumatların itməsi mümkünlüyünü bildirəcək.
- Geo Redundant Storage (GRS) təhlükəsizliyin və uzunömürlülüyün daha yüksək dərəcəsini təqdim edir. Məlumat replikalarını ancaq Primary coğrafi lokasiyada deyil, həmçinin həmin regionda, amma yüzlərlə kilometr aralıqda olan data mərkəzlərdə yerləşdirir. Blobların və cədvəllərin servis storage-ində yerləşən məlumatlar coğrafi replikasiyaya məruz qalırlar. Coğrafi replikasiya edilmiş storage-də platforma yenə 3 replika formasında saxlanılır. Ümumilikdə hər iki lokasiyada 6 nüsxə saxlanılır.
Beləliklə, əgər Data Mərkəz əlçatan olmazsa, məlumatları ikinci lokasiyadan əldə etmək mümkün olur. Birinci Redundant funksiyasında, yəni LRS-də olduğu kimi, Primary coğrafi lokasiyadakı məlumat yazılması prosesinin uğurla nəticələnməsi haqqında kodu göndərməzdən əvvəl, bütün məlumatlar sistem səviyyəsində test olunur. Məlumatın təsdiqlənməsi bir lokasiyada yekunlaşdıqdan sonra isə, asinxron rejimdə başqa coğrafi lokasiyaya replikasiya başlayır.
İndi isə coğrafi replikasiyanın necə baş verməsi haqqında biraz ətraflı danışaq:
Siz, yaratma, silmə, yenilənmə əməliyyatlarını reallaşdıran zaman, tranzaksiya 3 fərqli Fault və Update domaində yerləşən (Primary coğrafi lokasiyada) tamamilə 3 fərqli storage Node-a replikasiya olunur. Bundan sonra müştəriyə əməliyyatın uğurla yerinə yetirilməsi kodu gondərilir və tranzaksiya asinxron rejimdə ikinci lokasiyaya replikasiya olunmağa başlayır, hansı ki, ikinci lokasiyada da Fault və Update domainlə 3 fərqli storage Node-a replikasiya olur. Bu prosseslər asinxron baş verdiyinə görə ümumi performansa ciddi təsir göstərmir.
Bəs daha ciddi qəzalar baş verdikdə hər şey necə bərpa olur?
Əgər, Primary coğrafi lokasiyada sistem qəzası baş verirsə, əlbəttə ki, Microsoft fəsadları mümkün qədər hiss edilmədən minimallaşdırmağa çalışır. Amma əgər bütün məlumatlar itirilibsə, müştəriyə Primary lokasiyada baş vermiş qəza haqqında məlumat verilir və lazım olan DNS recordlar Primary lokasiyadan ikincisinə yazılır (account.service.core.windows.net).
Aydın məsələdir ki, DNS-yazılar bitənə qədər storage-lə işləmək imkanı məhdudlaşacaqdır. Bu proses özlüyündə uzun vaxt almadığına görə ciddi itkilərin baş verməsi çətin məsələdir. Köçürülmə əməliyyatı bitdikdən sonra ikinci lokasiya Primary dərəcəli status alır (data mərkəzdə növbəti qəza olana qədər). Data Mərkəzin statusunun yüksəlməsi prosesi bitən kimi, həmin regionda ikinci coğrafi lokasiyanın yaradılmasına başlanılır və məlumatların replikasiyası davam edir.
Bunlar hamısı Fabric Controller vasitəsilə idarə olunur. Əgər virtual maşınlara quraşdırılan guest agentlər cavab verməsə, kontoller hər şeyi başqa Node-a miqrasiya edir. Sonra isə, əlçatanlığı təmin etmək üçün şəbəkə konfiqurasiyasını yenidən proqramlaşdırır. Haqqında yazdığımız Fault və Update domain mexanizmləri, Data Mərkəzdə əməliyyat sistemlərinin yenilənməsi və hətta fiziki problem olan avadanlıqların dəyişilməsi zamanı belə əlçatanlığı qoruyub saxlayır.
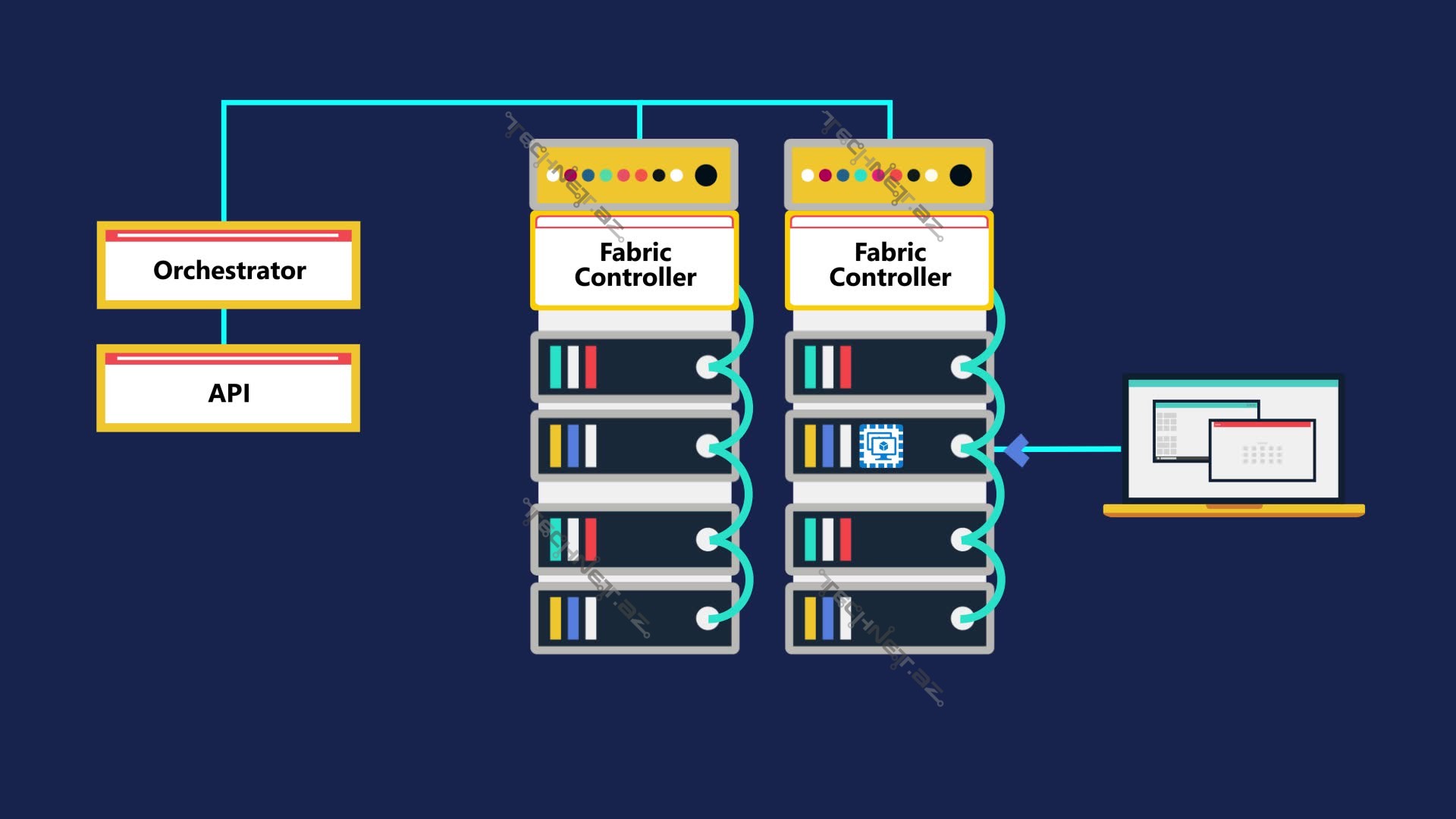
Fault domain – virtuallaşmış xüsusi bir fiziki elementdir, açılma konteyneridir və adətən rack ilə məhdudlaşır. Nəyə görə o rack ilə məhdudlaşıb? Çünki əgər fault domainlər müxtəlif rack-lərdə yerləşərlərsə, nümunələrin eyni zamanda sıradan çıxmasının qarşısı alınar. Bundan əlavə, bir fault domaindəki error digər domainlərdə də error yaranması ilə nəticələnməməlidir. Əgər fault domaində nəsə xarab olsa, bütün domain xarab olmuş kimi işarələnir və açılma başqa fault domainə keçirilir.
Update domainləri isə daha kontrol ediləndirlər. İstifadəçi öz servisinin nümunə qruplarının incremental və ya rolling update-lərini eyni zaman çərçivəsində edə bilər. Update domenləri məntiqi mahiyyət daşıyırlar, fault domainlər isə fiziki. Update domain role-ları məntiqi qrupladığına görə, bir proqram bir neçə Update domainlərində və eyni zamanda yalnız 2 fault domaində yerləşə bilər. Belə olduqda yenilənmə əvvəl n1 Update domainində sonra n2 və s. həyata keçirilir.

Hər Data Mərkəzdə minimum iki elektroenerji mənbəyi olur və bunlardan biri avtonom olaraq çalışır.
Son.


