Microsoft Failover Clustering 3-cü hissə (Hyper-V Clustering, Live Migration).
Salamlar hərkəsə bu məqaləmdə, keçən məqələlərimdə mövcud qurduğumuz cluster üzərində virtual maşın yaradaraq Live Migration və Failover məsələlərinə toxunacağam. İlk öncə cluster üzərində bir ədəd virtual maşın yaradacağıq və node-lar arasında migration edəcəyik, daha sonra isə olası bir fail zamanı cluster-in davranışına baxacağıq. Mənim daha əvvəlki məqalələrdə də istifadə etdiyim cluster-im üzərində sadəcə şəbəkə kartlarında dəyişiklik etmişəm , live migration üçün ayrıca bir şəbəkə kartı əlavə etmişəm. Cluster çalışdığı zaman bunu etmək üçün ilk öncə node-lardan birini pause etməliyik daha sonra cluster servisini saxlayaraq cluster-dan evict edib üzərində uyğun dəyişiklikləri aparırıq yenidən cluster-a daxil etməliyik daha sonra eyni prosesi digər node üçün də təkrarlamalı və həmin node-u da cluster-a daxil etdikdən sora cluster konfiqurasiyasını doğrulama əməliyyatını icra etməliyik. Beləliklə mənim cluster-imdə 4 şəbəkəm var;

Eyni zamanda mən burda Hyper-V node-lar üzərində bir external switch yaratmışam, hansı ki mənim yaradacağım virtual maşın bu switch-ə qoşulacaq, burda diqqət ediləsi bir məqam ondan ibarətdir ki, əgər bu virtual maşın high availability mode-da fəaliyyət göstərəcəyi üçün, əvvəlki node-da external switch-lə clientlər üçün xidmət verirsə, olası bir fail sırasında digər node üzərindən qalxarsa həmin adda switch axtarar, buna görə də hər iki node üzərində switch-lərin adı eyni olmalıdır. Biz cluster üzərində yeni virtual maşın yarada və ya node-lar üzərində mövcud virtual maşınları high availability mode-a ala bilərik, bunun üçün Configure Role deyərək Virtual Machine seçərək uyğun virtual maşınları high availability mode -da tənzimləyə bilərsiniz. Virtual maşının high avaibility mode-da çalışması üçün virtual disk və confiqurasiya faylları CSV (cluster shared volumes) üzərində olmalıdır. Bunu əvvəlcədən , yəni virtual maşını yaratmadan , ya da mövcud virtual maşını shared storage üzərində daşıya bilərik. İlk öncə daha asan olması üçün node-larımız üzərində Hyper-V -nin tənzimləmələrində yaradılacaq virtual maşınlar üçün virtual disk və konfiqurasiyaların saxlanacağı yerləri CSV üzərində təyin edirik:
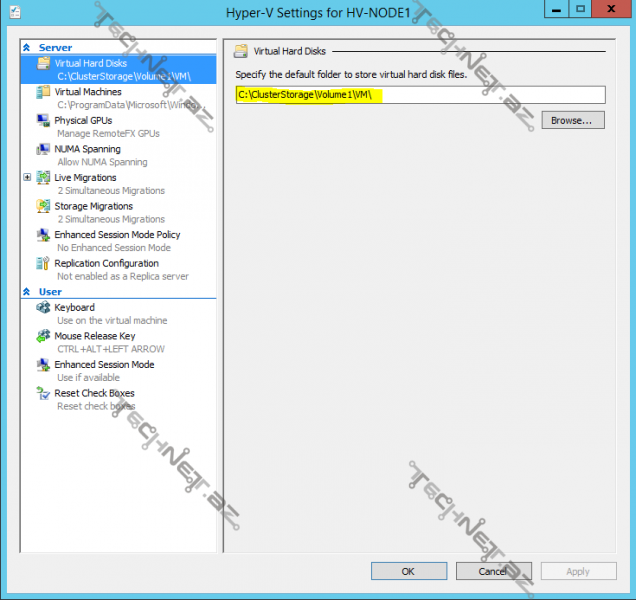

bunu hər iki node üçün də etdikdən sonra keçək virtual maşının yaradılmasına:
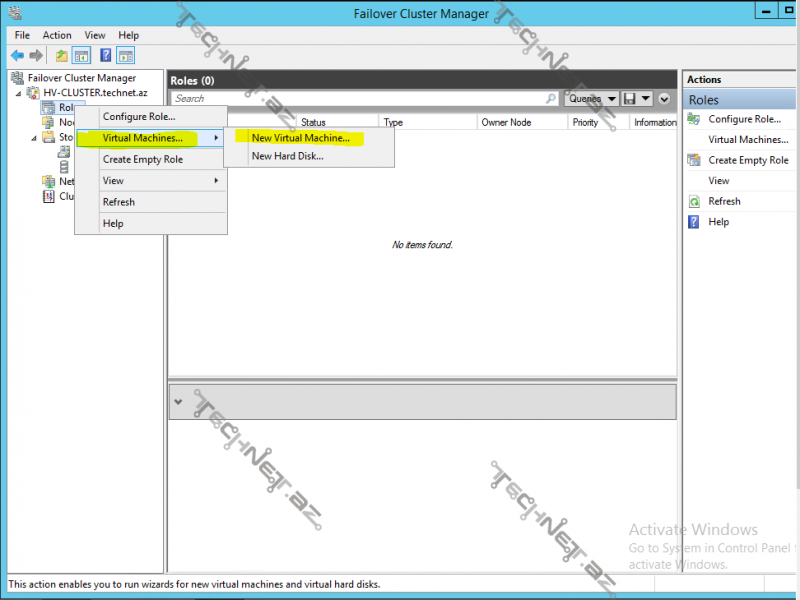
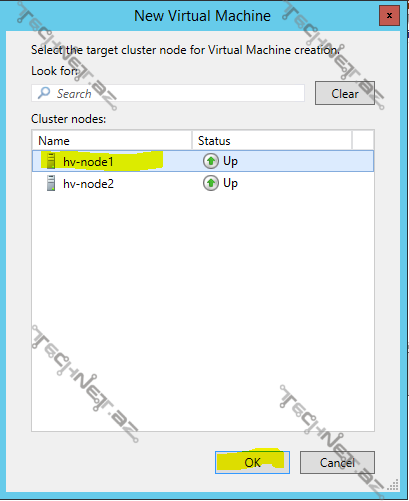
burada hansı node üzərində virtual maşın yaradacağımızı müəyyən edirik:
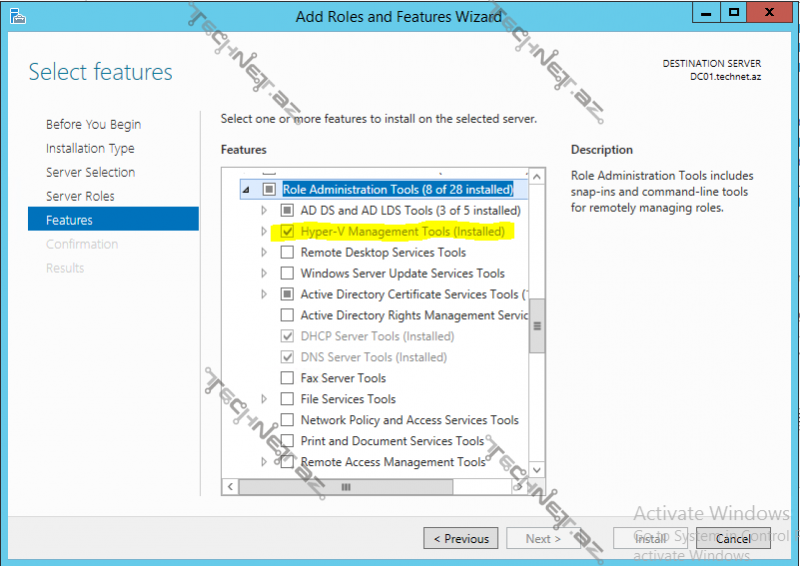
sonrakı mərhələ üçün cluster-i manage -etdiyimiz server üzərində aşağıdakı işarələnmiş features-lər yüklü olmalıdır:
New virtual machine dediyimiz zaman Hyper-V dən tanıdığımız wizard ilə qarşılaşırıq:

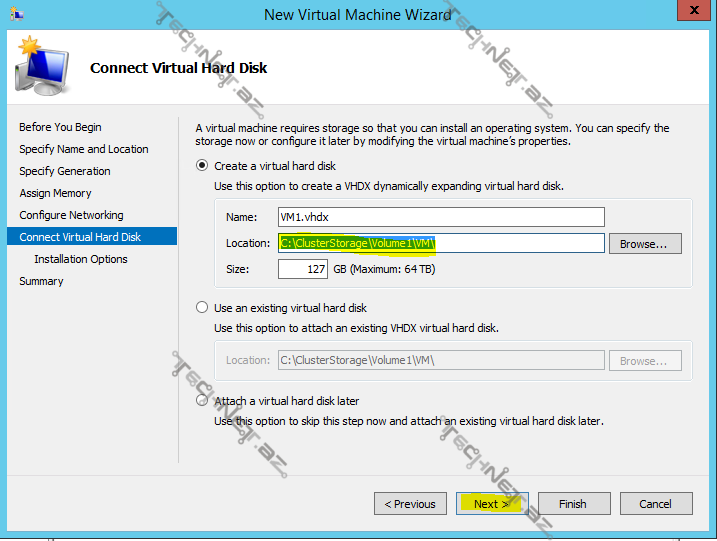
gördüyümüz kimi location bölməsində CSV üzərindəki bir qovluq göstərilib:



bu hissədə isə virtual maşınımızın mənim daha əvvəldən yaratdığım external switch-dən xidmət verməsini təmin edirik:

bu hissədə də gördüyümz kimi virtual diskimiz CSV üzırində yerləşəcək:
finish deyərək virtual maşınımızı yaratmış oluruq, bu zaman avtomatik olaraq virtual maşınımız high available olaraq tənzimlənəcəkdir:


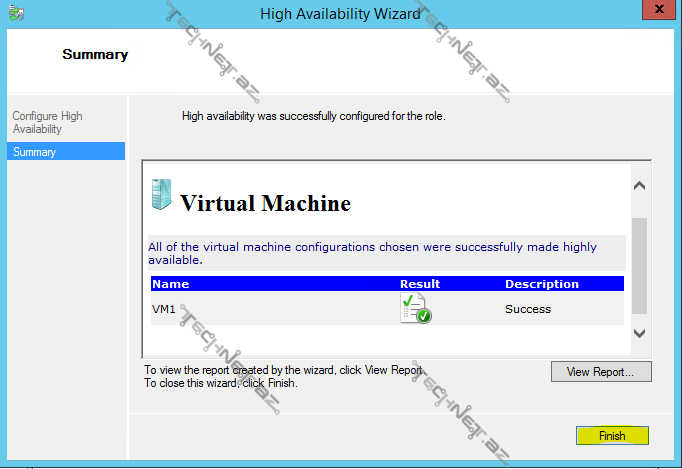
gördüyümüz kimi virtual maşınımız yaradıldı, işarəli hissələrdə virtual maşınımızın disk və konfiqurasiyasının yerləşdiyi diski və əlçatanlığı barədə məulmat ala bilərik:

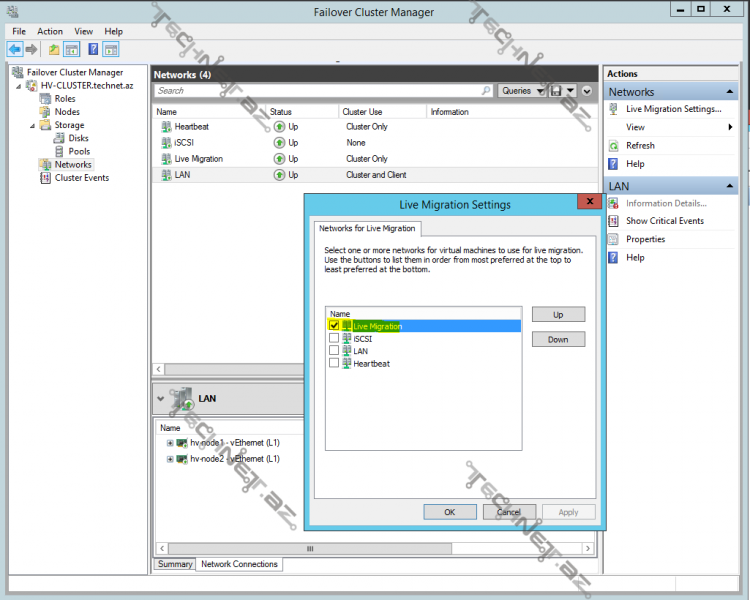
virtual maşınımızı işə salaraq xidmət verəcək bir hala gətirdikdən sonra keçək Live Migration-la bağlı tənzimləmələrə, network bölməsində Live Migration Settings -ə daxil oluruq:

Live Migration-unun həyata keçiriləcəyi şəbəkəni müəyyən edirik, həmçinin bir neçə şəbəkəni də seçə bilərik və həm də hansının ilk olaraq daha üstün tutulan olduğunu müəyyən edə bilərik:
Node-lar üzərində isə Hyper-V tənzimləmələrində Live Migration aktiv olmalıdır:

Beləliklə virtual maşınımız cluster daxilində public olaraq müəyyən etdiyimiz şəbəkədən xidmət verməkdədir:
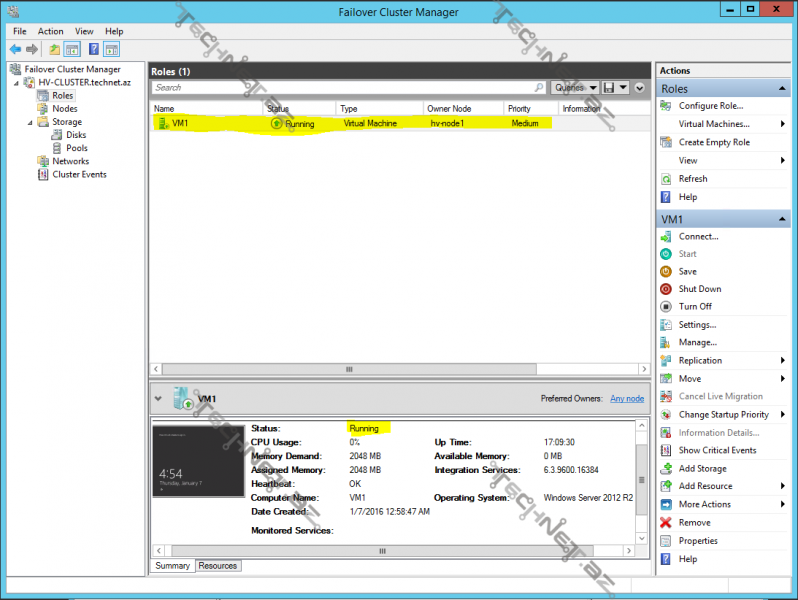

Virtual maşın üzərində sağ düyməni vurub move dediyimiz zaman 3 seçimimiz olacaqdır:
1-Live Migration – işlək vəziyyətdə olan node üzərindəki virtual maşının digər node üzərinə köcürülməsi.
2-Quick Migration- qısa bir xidmət kəsintisi ilə virtual maşının digər node üzərinə daşınması, hər hanı bir node-un fail olması zamanı virtual maşın bu yolla digər node üzərindən start olur.
3-Virtual Machine Storage- virtual maşının hər hansı digər bir shared storage üzərinə online olaraq daşınması.
Live və Quick Migration seçimləri ilə birlikdə iki seçimimiz var Best Possible Node və Select Node , yəni ən mümükün olan node və ya bizim seçdiyimiz node:

indi isə Live və Quick Migration-u test edək, ilk öncə VM1 üzərində sağ düymə ilə move daha sonra Live Migration>Best Possible Node deyək, gördüyümüz kimi migration başlandı:

gördüyümüz kimi qısa bir müddət ərzində virtual maşınımız hv-node2 üzərində daşındı:
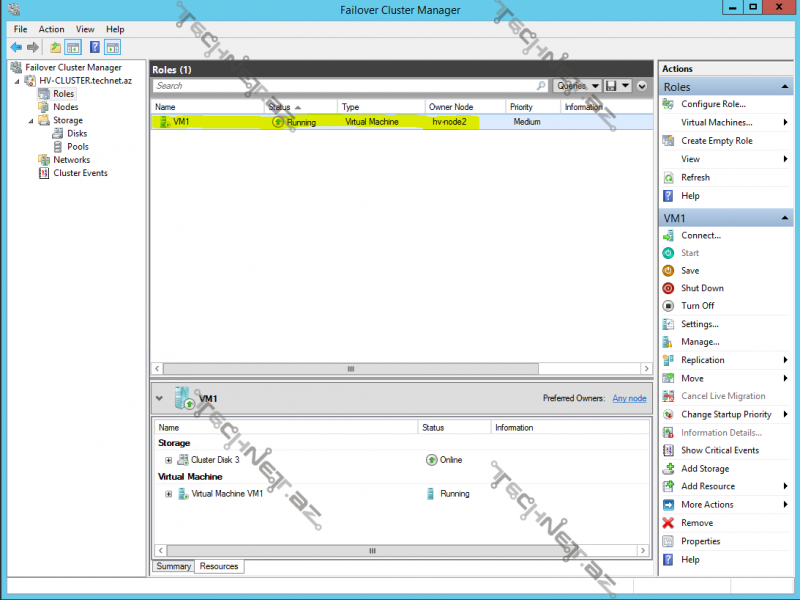
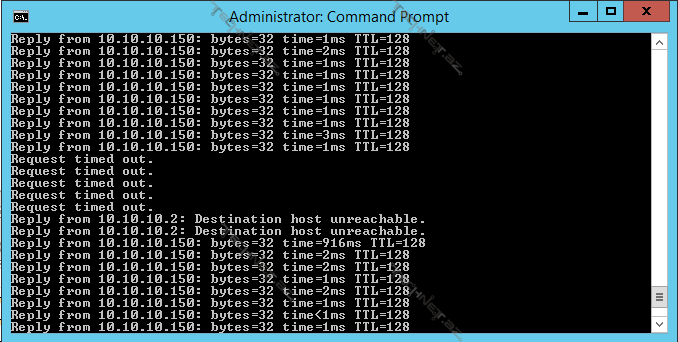
daşınma zamanı baş verən bu qısa time out hiss olunmur:

indi isə VM1 üzərində sağ düymə ilə Move >Quick Migration> Best Possible Node deyək, bu zaman gördüyümüz kimi VM1-in indiki vəziyyəti saxlanaraq pause olunur:
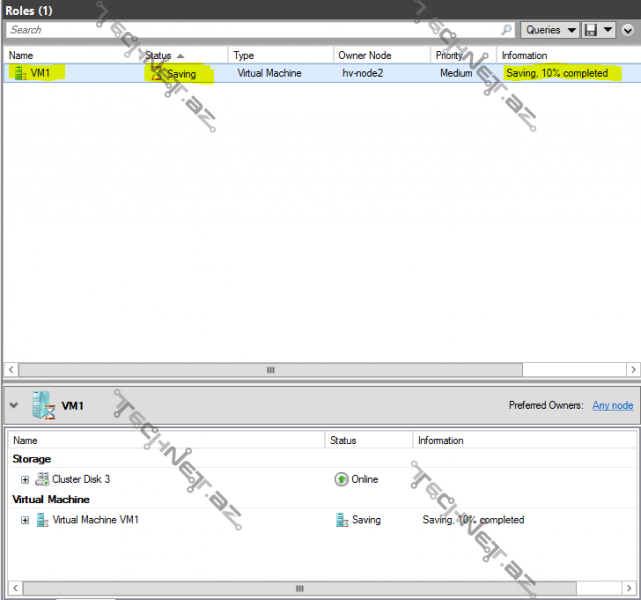
daha sonra isə digər node üzərindən start olunaraq xidmətə qaytarılır:

və çox qısa bir xidmət kəsintisi ilə:

İndi isə hər VM1-in üzərində olduğu node-un fail olması zamanı baş verəcəklərə baxaq, mən hv-node1 force olaraq shutdown edəcəyəm. gördüyümüz kimi VM1 maşınım hv-node1 üzərindədir, indi hv-node1-i force shutdown edək:
hv-node1 fail olan zaman VM1 maşınımız müəyyən bir downtime ilə digər hv-node2 üzərindən ayağa qalxacaqdır, əgər biz force yox adi qaydada shutdown etmiş olsaq o zaman ilk olaraq VM1 maşınımız hv-node2 üzərinə daşınacaq və node-daha sonra down olacaqdır:
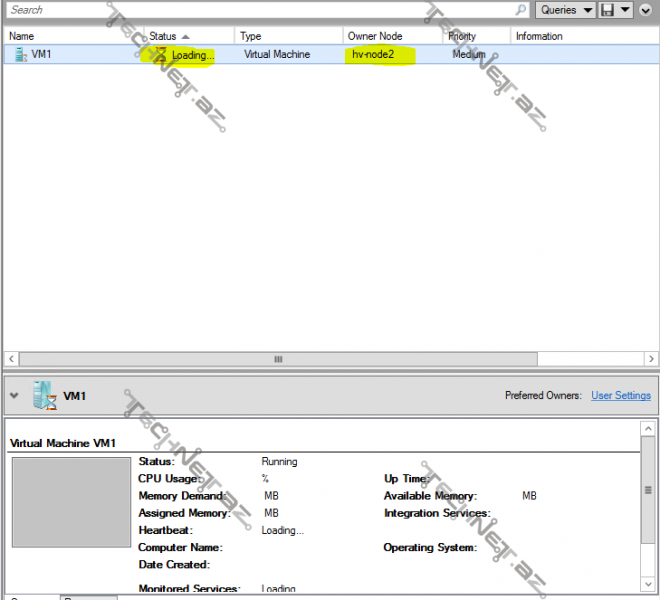
gördüyümüz kimi atrıq VM1 maşınımız hv-node2 üzərindədir:
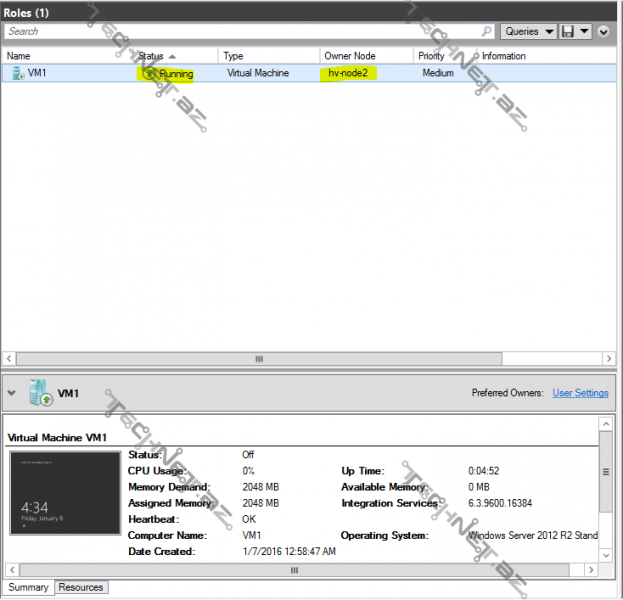
biz eyni zamanda fail olmuş node-umuz yenidən ayağa qalxıb cluster-a join olduqda VM1-i yenidən üzərinə almasını istəyə bilərik ki bu Failback adlanır, eyni zamanda cluster servisinin VM1-də olası hər hansı bir fail zamanı cluster role-umuzu (bu nümunədə VM1) yenidən başlatmasını da müəyyən edə bilərik ki, bu da Failover adlanır, VM1-in properties-inə daxil olduğumuz zaman :
aşağıdakı pəncərə ilə qarşılaşırıq, burda ilk olaraq Preffered Owner, yəni üstün tutulan sahib -virtual maşınımızın daha çox üstün tutulan sahib node kimi başa düşə bilərik, yəni Failback sırasında bu node virtual maşını öz üzərinə alacaq. Eyni zamanda bir neçə node-u seçib priority müəyyən edə bilərik:

burada ilk olaraq cluster servisinin müəyyən zaman aralığında maksimum neçə fail-dən sonra Cluster Role-unu yenidən başladacağını və fail olan node-un yenidən join olması ilə, ya həmin anda ,ya da müəyyən zaman intervalında virtual maşını öz üzərinə almasını müəyyən edirik:

Microsoft Failover Clustering məqaləmin 3-cü hissəsini burda bitirirəm, yararlı olması diləyilə…


