robots.txt nədir?
Salam dostlar.
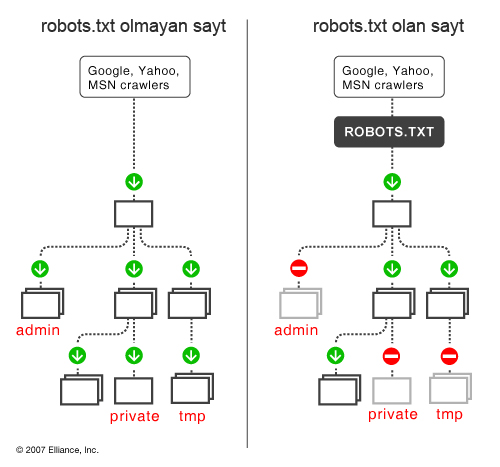
Deməli, məlunumuzdur ki, saytlar axtarış sistemlərinin (ro)botları tərəfindən incələnir(indexlənir), və saytın ibarət olduğu keçidlər, mətnlər və saytın tərkibindəki hər şey botlar tərəfindən axtarış sistemlərinin məlumat bazasına köçürülür. Nəticədə internetdə axtarış edən istifadəçi axtarış zamanı bizim saytımızla qarşılaşır təbii ki, əgər axtardığı şey bizim saytımızda varsa. 🙂
- Bəs yaxşı, botlar öz başına bizim saytımızı necə indexləyir?
- Hansı səhifələri indexləyir?
- Biz indexlənməsini istəmədiyimiz səhifələri botların gözündən necə gizlədək?
Axtarış sistemlərinin botlar bizim səhifələrimizi indexləmək üçün təşrif buyurduqları zaman ilk olaraq bizim saytın root qovluğunda /robots.txt faylının olub-olmadığını axtarırlar. Məsələn: www.saytimiz.com/robots.txt bot ilk öncə bu faylın içini oxuyur və saytda hansı səhifələrin və alt qovluqların indexlənməsinə icazə verilib verilmədiyinə baxır və buna müvafiq saytı indexləyir. Bəli, anladığınız kimi əgər biz saytımızda hər hansı səhifənin indexlənməyini istəmiriksə robots.txt ilə bunu edə bilərik.
Xüsusi Qeyd: Məqalədə sözü gedən botlar axtarış sistemlərinin(yəni, Google, Yahoo!, Bing və s.) leqal botlarıdır. Yəni bu botların işi doğurdan da səhifələri gəzib indexləyib axtarış sisteminə daxil etməkdir. Təəssüflər olsun ki. bəd niyyətlər üçün də botlar yazılıb və istifadə olunur. Bu botlar sizin səhifənizə gəldikləri zaman robots.txt qadağan etmələrinə təbii ki. məhəl qoymayacaqlar. Çoxları ümumiyyətlə robots.txt faylını açıb baxmır da. Onları əngəlləmək üçün ünvanlarını dəqiqləşdirib, .htaccess vasitəsi ilə qadağa qoymaq olar.
Nümunə: http://en.wikipedia.org/robots.txt və http://google.com/robots.txt
Gördüyünüz kimi dünyanın ən nəhəng layihələrindən olan axtarış sistemi Google və Pulsuz Ensiklopediya olan Wikipedia robots.txt faylından istifadə edirlər.
Gəlin indi robots.txt faylı yaradaq və yuxarıdakı nümunələrdən istifadə edib bu faylın işləmə məntiqini anlayaq.
- Sadəcə robots.txt adlı mətn faylı yaradırıq.(notepad proqramı yetərlidir 🙂 ) faylın adının hamısının kiçiklə olmasına diqqət edin. Robots.TXT və s. lazım deyil.
- User-agent: botun adını qeyd etmək üçündür. User-agent: yazıldıqdan sonra alt sətrdə icazə verilən və qadağan olunan səhifələr məhz User-Agent qabağında qeyd olunan bota şamil olunacaq. Əgər sadəcə *(ulduz) işarəsi varsa, bu icazə və qadağaların BÜTÜN botlara şamil olunması deməkdir.
- Disallow: Ingiliscədən tərcüməsi icazə verməməkdir. Bu terminin qarşısında olan səhifə və alt-qovluqlara botların girişi qadağan olunur. Beləliklə, bot bu disallovv qarşısında olan səhifə və qovluqları indexləmir.
- Allow: İngiliscədən tərcüməsi icazə verməkdir. Bur termin qarşısında olan səhifə və alt-qovluqlara botların girişinə icazə verilir və burda qeyd olunan səhifələr indexlənir.
robots.txt nümunəsi: Deməli bu faylda qeyd olunub ki, bütün botlara “/search” , “/sdch” və “/groups” qovluqları və onun içində yerləşən istənilən səhifə və qovluğun indexlənməsi qadağandır. Eləcə də “/catalogs/about” və “catalogs/p?” qovluqlarının indexlənməsinə icazə var.
User-agent: * Disallow: /search Disallow: /sdch Disallow: /groups Allow: /catalogs/about Allow: /catalogs/p?
Deyək ki, biz botlara individual olaraq icazə və qadağan qoymaq istəyirik. O zaman nə etməliyik?
Belə bir vəziyyəti təsəvvür edin. Saytımız.com saytımızda, “sekiller” adlı qovluğumuz var. Bu qovluğun bütün digər botlara qadağan olunmasını, Googlebot-a isə icazə verilməsini istəyirik. O zaman robots.txt faylımızın tərkibi bu cür olmalıdır.
User-agent: * Disallow: /sekiller User-agent: Google Allow: /sekiller
və sonda əgər ümumiyyətlə botlara səhifəmizi indexləmələrini qadağan etmək istəyiriksə, faylımızın tərkibi bu cür olacaq.
User-agent: * Disallow: /
Ümid edirəm ki, bu dərslik faydalı olacaq. Uğurlar 🙂


